भाग 2: nf-core के लिए Hello को फिर से लिखना¶
AI-सहायता प्राप्त अनुवाद - अधिक जानें और सुधार सुझाएं
Hello nf-core प्रशिक्षण पाठ्यक्रम के इस दूसरे भाग में, हम तुम्हें दिखाते हैं कि Hello Nextflow शुरुआती पाठ्यक्रम द्वारा तैयार की गई pipeline का nf-core संगत संस्करण कैसे बनाया जाए।
हम यह दो चरणों में करेंगे: पहले, हम nf-core tooling का उपयोग करके एक pipeline scaffold बनाएंगे, फिर मौजूदा 'नियमित' pipeline कोड को scaffold पर graft करेंगे।
यदि तुम Hello pipeline से परिचित नहीं हो या तुम्हें याद दिलाने की आवश्यकता है, तो यह जानकारी पेज देखो।
सुझाव
इस course का यह भाग दो महत्वपूर्ण Nextflow mechanisms पेश करेगा जो Hello Nextflow introductory course में cover नहीं किए गए हैं: meta maps और workflows of workflows, जो दोनों linked Side Quests में विस्तार से cover किए गए हैं।
नीचे दिए गए निर्देशों में वह आवश्यक जानकारी शामिल है जो तुम्हें यह समझने के लिए चाहिए कि इन्हें nf-core context में कैसे उपयोग किया जाता है, लेकिन एक साथ बहुत कुछ समझना मुश्किल हो सकता है। यदि तुम्हारे पास समय हो, तो हम recommend करते हैं कि पहले दोनों Side Quests पूरे करो (किसी भी क्रम में):
नोट
सुनिश्चित करो कि तुम अपने terminal में hello-nf-core डायरेक्टरी में हो।
1. Pipeline code structure की जांच करें¶
nf-core project इस बारे में कड़े दिशानिर्देश लागू करता है कि pipelines कैसे structured हों, और code कैसे organize, configure और document किया जाए।
Pipeline निर्माण project शुरू करने से पहले, हमें उस structure और organization को समझना होगा।
तो आइए देखें कि nf-core/demo repository में pipeline code कैसे organize किया गया है, उस pipelines symlink का उपयोग करके जो हमने भाग 1 में बनाया था।
याद दिलाने के लिए, तुम tree का उपयोग कर सकते हो या file explorer का उपयोग करके nf-core/demo डायरेक्टरी खोज सकते हो।
डायरेक्टरी सामग्री
pipelines/nf-core/demo
├── assets
├── CHANGELOG.md
├── CITATIONS.md
├── CODE_OF_CONDUCT.md
├── conf
├── docs
├── LICENSE
├── main.nf
├── modules
├── modules.json
├── nextflow.config
├── nextflow_schema.json
├── nf-test.config
├── README.md
├── ro-crate-metadata.json
├── subworkflows
├── tests
├── tower.yml
└── workflows
अभी के लिए हम विशेष रूप से pipeline code components (main.nf, workflows, subworkflows, modules) और वे एक दूसरे से कैसे संबंधित हैं, इस पर ध्यान केंद्रित करेंगे।
1.1. nf-core workflows की modular structure¶
मानक nf-core pipeline code organization एक modular structure का पालन करती है जो code reuse को अधिकतम करने के लिए designed है, जैसा कि Hello Modules में पेश किया गया था, Hello Nextflow course के भाग 4 में, हालांकि सच्चे nf-core fashion में, इसे थोड़ी अतिरिक्त जटिलता के साथ implement किया गया है। विशेष रूप से, nf-core pipelines subworkflows का भरपूर उपयोग करती हैं, यानी workflow scripts जो एक parent workflow द्वारा import की जाती हैं।
यह थोड़ा abstract लग सकता है, तो आइए देखें कि nf-core/demo pipeline में यह व्यवहार में कैसे उपयोग किया जाता है।
यदि तुम main.nf फ़ाइल के अंदर देखो, तो तुम देखोगे कि यह workflows/demo.nf से DEMO नाम की एक workflow import करती है, साथ ही कुछ modules और subworkflows भी।
यहाँ relevant code components के बीच संबंध इस तरह दिखते हैं:
main.nf में unnamed workflow को entrypoint script कहा जाता है। यह दो प्रकार के nested workflows के लिए एक wrapper के रूप में काम करती है: DEMO workflow जिसमें actual analysis logic है, workflows/demo.nf में स्थित है, और subworkflows/ के तहत स्थित housekeeping workflows का एक set।
demo.nf workflow modules/ के तहत स्थित modules को call करती है; इनमें वे processes हैं जो actual analysis steps perform करेंगे।
नोट
Subworkflows housekeeping functions तक सीमित नहीं हैं, और वे process modules का उपयोग कर सकते हैं।
यहाँ दिखाई गई nf-core/demo pipeline spectrum पर सरल side पर है, लेकिन अन्य nf-core pipelines (जैसे nf-core/rnaseq) subworkflows का उपयोग करती हैं जो actual analysis में शामिल होते हैं।
अब, आइए इन components को विस्तार से देखें।
1.2. Entrypoint script: main.nf¶
main.nf script वह entrypoint है जहाँ से Nextflow शुरू होता है जब हम nextflow run nf-core/demo execute करते हैं।
इसका मतलब है कि जब तुम pipeline चलाने के लिए nextflow run nf-core/demo चलाते हो, तो Nextflow स्वचालित रूप से main.nf script खोजता और execute करता है।
यह किसी भी Nextflow pipeline के लिए काम करता है जो इस conventional naming और structure का पालन करती है, न केवल nf-core pipelines के लिए।
Entrypoint script का उपयोग करने से actual analysis script चलने से पहले और बाद में standardized 'housekeeping' subworkflows चलाना आसान हो जाता है। हम actual analysis workflow और उसके modules की समीक्षा करने के बाद उन पर जाएंगे।
1.3. Analysis script: workflows/demo.nf¶
workflows/demo.nf workflow वह जगह है जहाँ pipeline की central logic संग्रहीत है।
यह एक normal Nextflow workflow की तरह structured है, सिवाय इसके कि इसे parent workflow से call किया जाने के लिए designed किया गया है, जिसके लिए कुछ अतिरिक्त features की आवश्यकता है।
हम इस course के अगले भाग में relevant differences cover करेंगे, जब हम Hello Nextflow से simple Hello pipeline को nf-core-compatible form में convert करने का काम करेंगे।
demo.nf workflow modules/ के तहत स्थित modules को call करती है, जिन्हें हम आगे देखेंगे।
नोट
कुछ nf-core analysis workflows lower-level subworkflows को call करके nesting के अतिरिक्त levels दिखाती हैं। यह मुख्य रूप से दो या अधिक modules को wrap करने के लिए उपयोग किया जाता है जो आमतौर पर एक साथ उपयोग किए जाते हैं, उन्हें easily reusable pipeline segments में बदलने के लिए। तुम nf-core website पर उपलब्ध nf-core subworkflows browse करके कुछ examples देख सकते हो।
जब analysis script subworkflows का उपयोग करती है, तो वे subworkflows/ डायरेक्टरी के तहत संग्रहीत होते हैं।
1.4. Modules¶
Modules वह जगह है जहाँ process code रहता है, जैसा कि Hello Nextflow training course के भाग 4 में बताया गया है।
nf-core project में, modules एक multi-level nested structure का उपयोग करके organize किए जाते हैं जो उनकी origin और उनकी contents दोनों को reflect करती है।
Top level पर, modules को nf-core या local (nf-core project का हिस्सा नहीं) के रूप में differentiate किया जाता है, और फिर उस tool(s) के नाम पर एक डायरेक्टरी में रखा जाता है जिसे वे wrap करते हैं।
यदि tool किसी toolkit का हिस्सा है (यानी एक package जिसमें कई tools हैं) तो toolkit के नाम पर एक intermediate directory level होता है।
तुम इसे nf-core/demo pipeline modules में व्यवहार में लागू देख सकते हो:
डायरेक्टरी सामग्री
यहाँ तुम देख सकते हो कि fastqc और multiqc modules nf-core modules के भीतर top level पर हैं, जबकि trim module उस toolkit के तहत है जिससे वह संबंधित है, seqtk।
इस case में कोई local modules नहीं हैं।
Process को describe करने वाली module code फ़ाइल को हमेशा main.nf कहा जाता है, और इसके साथ tests और .yml फ़ाइलें होती हैं जिन्हें हम अभी के लिए ignore करेंगे।
कुल मिलाकर, entrypoint workflow, analysis workflow और modules pipeline के 'interesting' हिस्सों को चलाने के लिए पर्याप्त हैं। हालाँकि, हम जानते हैं कि वहाँ housekeeping subworkflows भी हैं, तो आइए अब उन्हें देखें।
1.5. Housekeeping subworkflows¶
Modules की तरह, subworkflows को local और nf-core डायरेक्टरी में differentiate किया जाता है, और प्रत्येक subworkflow की अपनी nested directory structure होती है जिसमें अपना main.nf script, tests और .yml फ़ाइल होती है।
डायरेक्टरी सामग्री
pipelines/nf-core/demo/subworkflows
├── local
│ └── utils_nfcore_demo_pipeline
│ └── main.nf
└── nf-core
├── utils_nextflow_pipeline
│ ├── main.nf
│ ├── meta.yml
│ └── tests
├── utils_nfcore_pipeline
│ ├── main.nf
│ ├── meta.yml
│ └── tests
└── utils_nfschema_plugin
├── main.nf
├── meta.yml
└── tests
9 directories, 7 files
जैसा कि ऊपर उल्लेख किया गया है, nf-core/demo pipeline में कोई analysis-specific subworkflows नहीं हैं, इसलिए यहाँ दिखाई देने वाले सभी subworkflows तथाकथित 'housekeeping' या 'utility' workflows हैं, जैसा कि उनके नामों में utils_ prefix से पता चलता है।
ये subworkflows console output में fancy nf-core header produce करते हैं, अन्य accessory functions के साथ।
सुझाव
उनके naming pattern के अलावा, एक और indication कि ये subworkflows कोई truly analysis-related function perform नहीं करते, यह है कि वे कोई processes call नहीं करते।
यह nf-core/demo pipeline बनाने वाले core code components का round-up पूरा करता है।
सारांश¶
अब तुम्हें nf-core pipelines की modular structure की high-level समझ है।
आगे क्या है?¶
nf-core tooling का उपयोग करके एक pipeline scaffold बनाओ।
2. एक नया pipeline प्रोजेक्ट बनाएं¶
जैसा कि तुमने देखा है, nf-core pipelines कई accessory files के साथ एक standardized structure का पालन करती हैं। यह सब शुरू से बनाना बहुत थकाऊ होगा, इसलिए nf-core समुदाय ने इस प्रक्रिया को bootstrap करने के लिए एक template से यह करने के लिए tooling विकसित की है।
2.1. Template-आधारित pipeline निर्माण tool चलाएं¶
आइए nf-core pipelines create कमांड के साथ एक नया pipeline बनाकर शुरू करें।
यह nf-core base template का उपयोग करके एक नया pipeline scaffold बनाएगा, जिसे pipeline नाम, विवरण और लेखक के साथ अनुकूलित किया गया है।
इस कमांड को चलाने से pipeline निर्माण के लिए एक Text User Interface (TUI) खुलेगा:
यह TUI तुमसे अपने pipeline के बारे में बुनियादी जानकारी प्रदान करने के लिए कहेगा और तुम्हें अपने pipeline scaffold में शामिल करने या बाहर करने के लिए features का विकल्प देगा।
- स्वागत स्क्रीन पर, Let's go! पर क्लिक करो।
Choose pipeline typeस्क्रीन पर, Custom पर क्लिक करो।- अपनी pipeline का विवरण निम्नानुसार दर्ज करो (
< YOUR NAME >को अपने नाम से बदलो), फिर Next पर क्लिक करो।
[ ] GitHub organisation: core
[ ] Workflow name: hello
[ ] A short description of your pipeline: A basic nf-core style version of Hello Nextflow
[ ] Name of the main author(s): < YOUR NAME >
- Template features स्क्रीन पर,
Toggle all featuresको off पर सेट करो, फिर निम्नलिखित को चुनिंदा रूप से enable करो। अपने चयनों की जांच करो और Continue पर क्लिक करो।
[ ] Add testing profiles
[ ] Use nf-core components
[ ] Use nf-schema
[ ] Add configuration files
[ ] Add documentation
Final detailsस्क्रीन पर, Finish पर क्लिक करो। Pipeline बनने तक प्रतीक्षा करो, फिर Continue पर क्लिक करो।- Create GitHub repository स्क्रीन पर, Finish without creating a repo पर क्लिक करो। यह बाद में GitHub repository बनाने के निर्देश प्रदर्शित करेगा। इन्हें अनदेखा करो और Close पर क्लिक करो।
एक बार TUI बंद हो जाने के बाद, तुम्हें निम्नलिखित console output दिखाई देना चाहिए।
कमांड आउटपुट
Console output में कोई स्पष्ट पुष्टि नहीं है कि pipeline निर्माण सफल रहा, लेकिन तुम्हें core-hello नाम की एक नई डायरेक्टरी दिखाई देनी चाहिए।
नई डायरेक्टरी की सामग्री देखो कि template का उपयोग करके तुमने अपने आप को कितना काम बचाया।
डायरेक्टरी सामग्री
core-hello/
├── README.md
├── assets
│ ├── samplesheet.csv
│ └── schema_input.json
├── conf
│ ├── base.config
│ ├── modules.config
│ ├── test.config
│ └── test_full.config
├── docs
│ ├── README.md
│ ├── output.md
│ └── usage.md
├── main.nf
├── modules.json
├── nextflow.config
├── nextflow_schema.json
├── subworkflows
│ ├── local
│ │ └── utils_nfcore_hello_pipeline
│ │ └── main.nf
│ └── nf-core
│ ├── utils_nextflow_pipeline
│ │ ├── main.nf
│ │ ├── meta.yml
│ │ └── tests
│ │ ├── main.function.nf.test
│ │ ├── main.function.nf.test.snap
│ │ ├── main.workflow.nf.test
│ │ └── nextflow.config
│ ├── utils_nfcore_pipeline
│ │ ├── main.nf
│ │ ├── meta.yml
│ │ └── tests
│ │ ├── main.function.nf.test
│ │ ├── main.function.nf.test.snap
│ │ ├── main.workflow.nf.test
│ │ ├── main.workflow.nf.test.snap
│ │ └── nextflow.config
│ └── utils_nfschema_plugin
│ ├── main.nf
│ ├── meta.yml
│ └── tests
│ ├── main.nf.test
│ ├── nextflow.config
│ └── nextflow_schema.json
└── workflows
└── hello.nf
15 directories, 34 files
यह बहुत सारी फ़ाइलें हैं! चिंता मत करो यदि तुम थोड़ा खोया हुआ महसूस कर रहे हो; हम जल्द ही महत्वपूर्ण भागों के माध्यम से चलेंगे, और फिर course के बाकी हिस्से में step by step।
कुल मिलाकर, यह nf-core/demo pipeline के लिए हमने जो code structure देखी थी उससे मिलती-जुलती होनी चाहिए, सिवाय इसके कि यहाँ कोई modules डायरेक्टरी नहीं है।
2.2. जांचें कि scaffold कार्यात्मक है¶
विश्वास करो या न करो, भले ही तुमने अभी तक वास्तविक कार्य करने के लिए कोई modules नहीं जोड़े हैं, pipeline scaffold को वास्तव में test profile का उपयोग करके चलाया जा सकता है, उसी तरह जैसे हमने nf-core/demo pipeline चलाई थी।
कमांड आउटपुट
N E X T F L O W ~ version 25.10.4
Launching `./core-hello/main.nf` [scruffy_marconi] DSL2 - revision: b9e9b3b8de
Downloading plugin nf-schema@2.5.1
Input/output options
input : https://raw.githubusercontent.com/nf-core/test-datasets/viralrecon/samplesheet/samplesheet_test_illumina_amplicon.csv
outdir : core-hello-results
Institutional config options
config_profile_name : Test profile
config_profile_description: Minimal test dataset to check pipeline function
Generic options
trace_report_suffix : 2025-11-21_04-47-18
Core Nextflow options
runName : scruffy_marconi
containerEngine : docker
launchDir : /workspaces/training/hello-nf-core
workDir : /workspaces/training/hello-nf-core/work
projectDir : /workspaces/training/hello-nf-core/core-hello
userName : root
profile : docker,test
configFiles : /workspaces/training/hello-nf-core/core-hello/nextflow.config
!! Only displaying parameters that differ from the pipeline defaults !!
------------------------------------------------------
-[core/hello] Pipeline completed successfully-
यह तुम्हें दिखाता है कि सभी बुनियादी wiring जगह पर है। तो outputs कहाँ हैं? क्या कोई हैं?
वास्तव में, core-hello-results नाम की परिणामों की एक नई डायरेक्टरी बनाई गई थी जिसमें मानक execution reports हैं:
डायरेक्टरी सामग्री
core-hello-results
└── pipeline_info
├── execution_report_2025-11-21_04-47-18.html
├── execution_timeline_2025-11-21_04-47-18.html
├── execution_trace_2025-11-21_04-47-18.txt
├── hello_software_versions.yml
├── params_2025-11-21_04-47-18.json
└── pipeline_dag_2025-11-21_04-47-18.html
1 directory, 6 files
तुम reports देख सकते हो कि क्या चलाया गया था, और जवाब है: बिल्कुल कुछ भी नहीं!

आइए देखें कि box में वास्तव में क्या है।
2.3. Scaffold structure की जांच करें¶
यदि तुम्हें nf-core/demo pipeline की structure याद है, तो एक main.nf फ़ाइल थी जिसमें एक entrypoint workflow था जो DEMO workflow को wrap करता था।
अब यदि तुम अपने नए बनाए गए project में main.nf फ़ाइल खोलो, तो तुम देखोगे कि यह workflows/hello.nf से HELLO नाम की एक workflow import करती है।
यह DEMO workflow का direct equivalent है, हालांकि अभी यह सिर्फ एक placeholder है।
और तदनुसार, pipeline scaffold की overall structure इस तरह दिखती है:
यह तुम्हें nf-core/demo pipeline structure की याद दिलाना चाहिए!
एकमात्र वास्तविक अंतर यह है कि DEMO workflow में modules से processes शामिल थे।
यहाँ, equivalent HELLO workflow में अभी तक कोई processes नहीं हैं।
आइए करीब से देखें।
2.4. Placeholder workflow की जांच करें¶
यह हमारी analysis workflow के लिए placeholder के रूप में काम करती है, जिसमें कुछ nf-core कार्यक्षमता पहले से ही मौजूद है।
Hello Nextflow में विकसित की गई बुनियादी Nextflow workflow की तुलना में, तुम कुछ चीजें देखोगे जो यहाँ नई हैं (ऊपर highlighted पंक्तियाँ):
- Workflow block का एक नाम है
- Workflow inputs को
take:keyword का उपयोग करके घोषित किया जाता है और channel निर्माण को parent workflow में ऊपर ले जाया जाता है - Workflow सामग्री को
main:block के अंदर रखा गया है - Outputs को
emit:keyword का उपयोग करके घोषित किया जाता है
ये Nextflow की वैकल्पिक विशेषताएं हैं जो workflow को composable बनाती हैं, जिसका अर्थ है कि इसे किसी अन्य workflow के भीतर से बुलाया जा सकता है।
Channel.topic block
तुमने शायद line 17 से शुरू होने वाला def topic_versions = Channel.topic("versions") block देखा होगा।
यह boilerplate housekeeping कोड है जो सभी modules से software version की जानकारी स्वचालित रूप से collect करता है।
nf-core 2026 में सभी pipelines में इस mechanism को लागू कर रहा है, इसलिए तुम इसे आगे आने वाले सभी नए pipelines में देखोगे।
इस course का भाग 4 विस्तार से बताता है कि यह कैसे काम करता है।
हमें अपनी रुचि की workflow से प्रासंगिक logic को उस structure में plug करने की आवश्यकता है।
सारांश¶
अब तुम जानते हो कि nf-core tools का उपयोग करके pipeline scaffold कैसे बनाया जाए और इसे demo pipeline structure से कैसे compare किया जाए।
आगे क्या है?¶
एक सरल workflow को composable बनाने का तरीका सीखो जो इसे nf-core संगत बनाने के लिए एक प्रस्तावना के रूप में है।
3. एक composable Hello Nextflow workflow बनाएं¶
अब अपने workflow को nf-core scaffold में integrate करने का काम शुरू करने का समय आ गया है।
याद रखो, हम Hello Nextflow प्रशिक्षण पाठ्यक्रम में दिखाई गई workflow के साथ काम कर रहे हैं। वह workflow एक साधारण unnamed workflow के रूप में लिखी गई थी जिसे अपने आप चलाया जा सकता है।
यह clearly map करने के लिए कि original workflow के कौन से हिस्से nf-core scaffold में कहाँ जाने चाहिए, हम पहले original Hello workflow को एक composable workflow में transform करेंगे जिसे parent workflow के भीतर से चलाया जा सकता है, जैसा कि nf-core template की आवश्यकता है।
यह वह है जो हम अभी बनाने की कोशिश कर रहे हैं:
प्रभावी रूप से, हम nf-core scaffold की modular structure की नकल करना चाहते हैं, लेकिन शुरुआत में कम जटिलता के साथ।
हम तुम्हें original-hello डायरेक्टरी में पूर्ण Hello Nextflow workflow की एक साफ, पूरी तरह से कार्यात्मक प्रति प्रदान करते हैं, इसके modules और डिफ़ॉल्ट CSV फ़ाइल के साथ जिसे यह इनपुट के रूप में उपयोग करने की अपेक्षा करती है।
डायरेक्टरी सामग्री
अपने आप को संतुष्ट करने के लिए कि यह काम करता है, इसे चलाने के लिए स्वतंत्र महसूस करो:
कमांड आउटपुट
यदि यह तुम्हारे लिए काम करता है, तो तुम hacking शुरू करने के लिए तैयार हो।
3.1. Original Hello workflow को modify करें¶
आइए कोड का निरीक्षण करने के लिए hello.nf workflow फ़ाइल खोलें, जो नीचे पूर्ण रूप से दिखाया गया है (processes को छोड़कर, जो modules में हैं):
जैसा कि तुम देख सकते हो, यह workflow एक साधारण unnamed workflow के रूप में लिखी गई थी जिसे अपने आप चलाया जा सकता है। इसे composable बनाने के लिए, हम निम्नलिखित बदलाव करेंगे:
- Workflow को नाम दो
- Channel निर्माण को
take:से बदलो - Workflow operations से पहले
main:लगाओ emit:statement जोड़ो
आइए आवश्यक बदलावों के माध्यम से एक-एक करके चलें।
3.1.1. Workflow को नाम दें¶
सबसे पहले, आइए workflow को एक नाम दें ताकि हम इसे parent workflow से संदर्भित कर सकें।
वही conventions workflow नामों पर लागू होते हैं जो module नामों पर लागू होते हैं।
3.1.2. Channel निर्माण को take से बदलें¶
अब, channel निर्माण को एक साधारण take statement से बदलो जो अपेक्षित inputs घोषित करता है।
यह inputs कैसे प्रदान किए जाते हैं इसके विवरण को parent workflow पर छोड़ देता है।
जब हम इस पर हैं, तो हम params.greeting = 'greetings.csv' लाइन को भी comment out कर सकते हैं।
नोट
यदि तुम्हारे पास Nextflow language server extension इंस्टॉल है, तो syntax checker तुम्हारे कोड को red squiggles के साथ light up करेगा।
ऐसा इसलिए है क्योंकि यदि तुम take: statement डालते हो, तो तुम्हारे पास main: भी होना चाहिए।
हम इसे अगले चरण में जोड़ेंगे।
3.1.3. Workflow operations से पहले main statement जोड़ें¶
इसके बाद, workflow के body में बुलाए गए बाकी operations से पहले एक main statement जोड़ो।
यह मूल रूप से कहता है 'यह वह है जो यह workflow करता है'।
3.1.4. emit statement जोड़ें¶
अंत में, एक emit statement जोड़ो जो घोषित करता है कि workflow के अंतिम outputs क्या हैं।
यह मूल workflow की तुलना में कोड में एक नया जोड़ है।
3.1.5. पूर्ण किए गए बदलावों का सारांश¶
यदि तुमने सभी बदलाव वर्णित के अनुसार किए हैं, तो तुम्हारी workflow अब इस तरह दिखनी चाहिए:
यह Nextflow को वह सब कुछ बताता है जो चाहिए सिवाय इनपुट channel में क्या feed करना है। यह parent workflow में परिभाषित किया जाएगा, जिसे entrypoint workflow भी कहा जाता है।
3.2. एक dummy entrypoint workflow बनाएं¶
अपने composable workflow को जटिल nf-core scaffold में integrate करने से पहले, आइए सत्यापित करें कि यह सही तरीके से काम करता है। हम isolation में composable workflow का परीक्षण करने के लिए एक साधारण dummy entrypoint workflow बना सकते हैं।
उसी original-hello डायरेक्टरी में main.nf नाम की एक blank फ़ाइल बनाओ।
निम्नलिखित कोड को main.nf फ़ाइल में copy करो।
यहाँ दो महत्वपूर्ण अवलोकन हैं:
- Imported workflow को बुलाने के लिए syntax मूल रूप से modules को बुलाने के लिए syntax के समान है।
- वह सब कुछ जो inputs को workflow में खींचने से संबंधित है (इनपुट पैरामीटर और channel निर्माण) अब इस parent workflow में घोषित किया गया है।
नोट
Entrypoint workflow फ़ाइल का नाम main.nf रखना एक convention है, आवश्यकता नहीं।
यदि तुम इस convention का पालन करते हो, तो तुम अपने nextflow run कमांड में workflow फ़ाइल का नाम निर्दिष्ट करना छोड़ सकते हो।
Nextflow स्वचालित रूप से execution डायरेक्टरी में main.nf नाम की फ़ाइल की तलाश करेगा।
हालाँकि, यदि तुम चाहो तो entrypoint workflow फ़ाइल को कुछ और नाम दे सकते हो।
उस स्थिति में, अपने nextflow run कमांड में workflow फ़ाइल का नाम निर्दिष्ट करना सुनिश्चित करो।
3.3. जांचें कि workflow चलता है¶
अंत में हमारे पास वह सभी टुकड़े हैं जो हमें यह सत्यापित करने के लिए चाहिए कि composable workflow काम करता है। आइए इसे चलाएं!
यहाँ तुम main.nf naming convention का उपयोग करने का लाभ देखते हो।
यदि हमने entrypoint workflow को something_else.nf नाम दिया होता, तो हमें nextflow run original-hello/something_else.nf करना पड़ता।
यदि तुमने सभी बदलाव सही तरीके से किए हैं, तो यह पूरा होने तक चलना चाहिए।
कमांड आउटपुट
N E X T F L O W ~ version 25.10.4
Launching `original-hello/main.nf` [friendly_wright] DSL2 - revision: 1ecd2d9c0a
executor > local (8)
[24/c6c0d8] HELLO:sayHello (3) | 3 of 3 ✔
[dc/721042] HELLO:convertToUpper (3) | 3 of 3 ✔
[48/5ab2df] HELLO:collectGreetings | 1 of 1 ✔
[e3/693b7e] HELLO:cowpy | 1 of 1 ✔
Output: /workspaces/training/hello-nf-core/work/e3/693b7e48dc119d0c54543e0634c2e7/cowpy-COLLECTED-test-batch-output.txt
इसका मतलब है कि हमने सफलतापूर्वक अपने HELLO workflow को composable बनाने के लिए upgrade किया है।
सारांश¶
तुम जानते हो कि इसे एक नाम देकर और take, main और emit statements जोड़कर एक workflow को composable कैसे बनाया जाए, और इसे entrypoint workflow से कैसे बुलाया जाए।
आगे क्या है?¶
जानो कि एक बुनियादी composable workflow को nf-core scaffold पर कैसे graft किया जाए।
4. Updated workflow logic को placeholder workflow में fit करें¶
अब जब हमने सत्यापित कर लिया है कि हमारी composable workflow सही तरीके से काम करती है, तो आइए section 1 में बनाए गए nf-core pipeline scaffold पर लौटें। हम अभी विकसित की गई composable workflow को nf-core template structure में integrate करना चाहते हैं, इसलिए अंतिम परिणाम कुछ इस तरह दिखना चाहिए।
तो हम इसे कैसे होने देते हैं? आइए core-hello/workflows/hello.nf (nf-core scaffold) में HELLO workflow की वर्तमान सामग्री देखें।
Highlighted पंक्तियाँ composable workflow की संरचना को परिभाषित करती हैं: workflow HELLO {, take:, main:, और emit:।
Lines 17–34 के बीच का बड़ा block अधिक महत्वपूर्ण है: यह topic channels का उपयोग करके software version capture को handle करता है, एक mechanism जिसे nf-core 2026 में सभी pipelines में लागू कर रहा है।
हम इसे भाग 4 में समझाएंगे; अभी के लिए, इसे boilerplate मानो जिसे तुम बिना छुए छोड़ सकते हो।
हमें section 2 में विकसित मूल workflow के composable संस्करण से प्रासंगिक कोड जोड़ने की आवश्यकता है।
हम इसे निम्नलिखित चरणों में निपटाने जा रहे हैं:
- Modules को copy करो और module imports सेट अप करो
takeघोषणा को जैसा है वैसा छोड़ दोmainblock में workflow logic जोड़ोemitblock को अपडेट करो
नोट
हम इस पहले pass के लिए version capture block को ignore करने जा रहे हैं। भाग 4 बताता है कि यह कैसे काम करता है।
4.1. Modules को copy करें और module imports सेट अप करें¶
हमारी Hello Nextflow workflow के चार processes original-hello/modules/ में modules के रूप में संग्रहीत हैं।
हमें उन modules को nf-core project structure (core-hello/modules/local/ के तहत) में copy करने और nf-core workflow फ़ाइल में import statements जोड़ने की आवश्यकता है।
पहले आइए module फ़ाइलों को original-hello/ से core-hello/ में copy करें:
अब तुम्हें core-hello/ के तहत modules की डायरेक्टरी सूचीबद्ध दिखाई देनी चाहिए।
डायरेक्टरी सामग्री
अब आइए module import statements सेट अप करें।
ये original-hello/hello.nf workflow में import statements थे:
| original-hello/hello.nf | |
|---|---|
core-hello/workflows/hello.nf फ़ाइल खोलो और उन import statements को नीचे दिखाए अनुसार इसमें transpose करो।
यहाँ दो और दिलचस्प अवलोकन हैं:
- हमने nf-core style convention का पालन करने के लिए import statements की formatting को अनुकूलित किया है।
- हमने modules के relative paths को यह reflect करने के लिए अपडेट किया है कि वे अब nesting के एक अलग स्तर पर संग्रहीत हैं।
4.2. take घोषणा को जैसा है वैसा छोड़ दें¶
nf-core project में samplesheet की अवधारणा के आसपास बहुत सारी पूर्व-निर्मित कार्यक्षमता है, जो आमतौर पर columnar डेटा वाली एक CSV फ़ाइल है।
चूंकि यह मूल रूप से वही है जो हमारी greetings.csv फ़ाइल है, हम वर्तमान take घोषणा को जैसा है वैसा रखेंगे, और अगले चरण में बस इनपुट channel के नाम को अपडेट करेंगे।
| core-hello/workflows/hello.nf | |
|---|---|
इनपुट handling इस workflow के upstream में की जाएगी (इस code फ़ाइल में नहीं)।
4.3. main block में workflow logic जोड़ें¶
अब जब हमारे modules workflow के लिए उपलब्ध हैं, तो हम workflow logic को main block में plug कर सकते हैं।
एक reminder के रूप में, यह मूल workflow में प्रासंगिक कोड है, जो जब हमने इसे composable बनाया तो बहुत अधिक नहीं बदला (हमने बस main: लाइन जोड़ी):
हमें main: के बाद आने वाले कोड को workflow के नए संस्करण में copy करने की आवश्यकता है।
इसमें पहले से ही कुछ कोड है जो workflow द्वारा चलाए जाने वाले tools के versions को capture करने से संबंधित है। हम अभी के लिए इसे अकेला छोड़ने जा रहे हैं (हम बाद में tool versions से निपटेंगे)।
हम शीर्ष पर ch_versions = channel.empty() initialization रखेंगे, फिर अपना workflow logic insert करेंगे, अंत में version collation कोड रखेंगे।
यह ordering समझ में आता है क्योंकि एक वास्तविक pipeline में, processes version information emit करेंगे जो workflow चलने के दौरान ch_versions channel में जोड़ी जाएगी।
तुम ध्यान देखोगे कि हमने कोड को अधिक readable बनाने के लिए main: से पहले एक blank लाइन भी जोड़ी।
यह बहुत अच्छा लगता है, लेकिन हमें अभी भी sayHello() process को pass किए जाने वाले channel के नाम को greeting_ch से ch_samplesheet में अपडेट करने की आवश्यकता है जैसा कि नीचे दिखाया गया है, take: keyword के तहत लिखे गए से match करने के लिए।
अब workflow logic सही तरीके से wired up है।
4.4. emit block को अपडेट करें¶
अंत में, हमें workflow के अंतिम outputs की घोषणा शामिल करने के लिए emit block को अपडेट करने की आवश्यकता है।
यह उन संशोधनों को पूरा करता है जो हमें HELLO workflow के लिए करने की आवश्यकता है। इस बिंदु पर, हमने उस समग्र code structure को प्राप्त कर लिया है जिसे हमने लागू करने के लिए निर्धारित किया था।
सारांश¶
तुम जानते हो कि एक composable workflow के मुख्य टुकड़ों को nf-core placeholder workflow में कैसे fit किया जाए।
आगे क्या है?¶
जानो कि nf-core pipeline scaffold में inputs को कैसे handle किया जाता है, इसे कैसे अनुकूलित करें।
5. इनपुट handling को अनुकूलित करें¶
अब जब हमने सफलतापूर्वक अपने workflow logic को nf-core scaffold में integrate कर लिया है, तो हमें एक और महत्वपूर्ण टुकड़े को संबोधित करने की आवश्यकता है: यह सुनिश्चित करना कि हमारा इनपुट डेटा सही तरीके से processed हो।
nf-core template जटिल genomics datasets के लिए डिज़ाइन की गई परिष्कृत इनपुट handling के साथ आता है, इसलिए हमें इसे अपनी सरल greetings.csv फ़ाइल के साथ काम करने के लिए अनुकूलित करने की आवश्यकता है।
5.1. पहचानें कि inputs कहाँ handle किए जाते हैं¶
पहला कदम यह पता लगाना है कि इनपुट handling कहाँ की जाती है।
तुम्हें याद होगा कि जब हमने Hello Nextflow workflow को composable बनाने के लिए फिर से लिखा था, तो हमने इनपुट पैरामीटर घोषणा को एक स्तर ऊपर, main.nf entrypoint workflow में ले जाया था।
तो आइए pipeline scaffold के हिस्से के रूप में बनाई गई शीर्ष स्तर main.nf entrypoint workflow देखें:
nf-core project nested subworkflows का भारी उपयोग करता है, इसलिए यह bit पहले approach पर थोड़ा confusing हो सकता है।
यहाँ जो मायने रखता है वह यह है कि दो workflows परिभाषित हैं:
CORE_HELLOcore-hello/workflows/hello.nfमें HELLO workflow को चलाने के लिए एक thin wrapper है जिसे हमने अभी अनुकूलित करना समाप्त किया।- एक unnamed workflow जो
CORE_HELLOके साथ-साथ दो अन्य subworkflows,PIPELINE_INITIALISATIONऔरPIPELINE_COMPLETIONको call करता है।
यहाँ एक diagram है कि वे एक दूसरे से कैसे संबंधित हैं:
महत्वपूर्ण रूप से, हम इस स्तर पर कोई इनपुट channel construct करने वाला कोड नहीं पा सकते हैं, केवल --input पैरामीटर के माध्यम से प्रदान की गई samplesheet के संदर्भ।
थोड़ा poke around करने से पता चलता है कि इनपुट handling PIPELINE_INITIALISATION subworkflow द्वारा की जाती है, उपयुक्त रूप से, जिसे core-hello/subworkflows/local/utils_nfcore_hello_pipeline/main.nf से import किया जाता है।
यदि हम उस फ़ाइल को खोलें और नीचे scroll करें, तो हम कोड के इस chunk पर आते हैं:
यह channel factory है जो samplesheet को parse करती है और इसे उस रूप में pass करती है जो HELLO workflow द्वारा consume करने के लिए तैयार है।
नोट
ऊपर दिया गया syntax हमने पहले उपयोग किए गए से थोड़ा अलग है, लेकिन मूल रूप से यह:
इसके बराबर है:
इस कोड में कुछ parsing और validation चरण शामिल हैं जो nf-core pipeline template के साथ शामिल उदाहरण samplesheet के लिए अत्यधिक specific हैं, जो लेखन के समय बहुत domain-specific है और हमारे सरल pipeline project के लिए उपयुक्त नहीं है।
5.2. Templated इनपुट channel कोड को बदलें¶
अच्छी खबर यह है कि हमारी pipeline की ज़रूरतें बहुत सरल हैं, इसलिए हम उस सभी को channel निर्माण कोड से बदल सकते हैं जो हमने मूल Hello Nextflow workflow में विकसित किया था।
एक reminder के रूप में, यह channel निर्माण कैसा दिखता था (जैसा कि solutions डायरेक्टरी में देखा गया है):
| solutions/composable-hello/main.nf | |
|---|---|
तो हमें बस इसे initialisation workflow में plug करने की आवश्यकता है, मामूली बदलावों के साथ: हम channel का नाम greeting_ch से ch_samplesheet में अपडेट करते हैं, और पैरामीटर नाम params.greeting से params.input में (highlighted लाइन देखो)।
| core-hello/subworkflows/local/utils_nfcore_hello_pipeline/main.nf | |
|---|---|
यह उन बदलावों को पूरा करता है जो हमें इनपुट processing को काम करने के लिए करने की आवश्यकता है।
इसके वर्तमान रूप में, यह हमें schema validation के लिए nf-core की built-in क्षमताओं का लाभ उठाने की अनुमति नहीं देगा, लेकिन हम इसे बाद में जोड़ सकते हैं। अभी के लिए, हम इसे यथासंभव सरल रखने पर ध्यान केंद्रित कर रहे हैं ताकि हम test data पर सफलतापूर्वक कुछ चला सकें।
5.3. Test profile को अपडेट करें¶
Test data और parameters की बात करें तो, आइए template में प्रदान की गई उदाहरण samplesheet के बजाय greetings.csv mini-samplesheet का उपयोग करने के लिए इस pipeline के test profile को अपडेट करें।
core-hello/conf के तहत, हम दो templated test profiles पाते हैं: test.config और test_full.config, जो एक छोटे data sample और एक full-size sample को test करने के लिए बनाए गए हैं।
हमारी pipeline के उद्देश्य को देखते हुए, full-size test profile सेट अप करने का वास्तव में कोई मतलब नहीं है, इसलिए test_full.config को ignore या delete करने के लिए स्वतंत्र महसूस करो।
हम कुछ default parameters के साथ हमारी greetings.csv फ़ाइल पर चलने के लिए test.config सेट अप करने पर ध्यान केंद्रित करेंगे।
5.3.1. greetings.csv फ़ाइल को copy करें¶
पहले हमें greetings.csv फ़ाइल को हमारे pipeline project में एक उपयुक्त स्थान पर copy करने की आवश्यकता है।
आमतौर पर छोटी test फ़ाइलें assets डायरेक्टरी में संग्रहीत की जाती हैं, इसलिए आइए हमारी working डायरेक्टरी से फ़ाइल को copy करें।
अब greetings.csv फ़ाइल test इनपुट के रूप में उपयोग के लिए तैयार है।
5.3.2. test.config फ़ाइल को अपडेट करें¶
अब हम test.config फ़ाइल को निम्नानुसार अपडेट कर सकते हैं:
मुख्य बिंदु:
${projectDir}का उपयोग: यह एक Nextflow implicit variable है जो उस डायरेक्टरी को point करती है जहाँ main workflow script स्थित है (pipeline root)। इसका उपयोग सुनिश्चित करता है कि path काम करेगा चाहे pipeline कहीं से भी चलाई जाए।- Absolute paths:
${projectDir}का उपयोग करके, हम एक absolute path बनाते हैं, जो pipeline के साथ ship होने वाले test data के लिए महत्वपूर्ण है। - Test data location: nf-core pipelines आमतौर पर छोटी test फ़ाइलों के लिए pipeline repository के भीतर
assets/डायरेक्टरी में test data संग्रहीत करती हैं, या बड़ी फ़ाइलों के लिए external test datasets का reference देती हैं।
और जब हम इस पर हैं, तो आइए default resource limits को कड़ा करें ताकि यह बहुत ही बुनियादी machines पर चले (जैसे Github Codespaces में minimal VMs):
यह हमें करने के लिए आवश्यक code modifications को पूरा करता है।
5.4. Test profile के साथ pipeline चलाएं¶
यह बहुत कुछ था, लेकिन हम अंत में pipeline चलाने की कोशिश कर सकते हैं!
ध्यान दो कि हमें command line में --validate_params false जोड़ना होगा क्योंकि हमने अभी तक validation सेट अप नहीं किया है (वह बाद में आएगा)।
यदि तुमने सभी modifications सही तरीके से किए हैं, तो यह पूरा होने तक चलना चाहिए।
कमांड आउटपुट
N E X T F L O W ~ version 25.10.4
Launching `core-hello/main.nf` [condescending_allen] DSL2 - revision: b9e9b3b8de
Input/output options
input : /workspaces/training/hello-nf-core/core-hello/assets/greetings.csv
outdir : core-hello-results
Institutional config options
config_profile_name : Test profile
config_profile_description: Minimal test dataset to check pipeline function
Generic options
validate_params : false
trace_report_suffix : 2025-11-21_07-29-37
Core Nextflow options
runName : condescending_allen
containerEngine : docker
launchDir : /workspaces/training/hello-nf-core
workDir : /workspaces/training/hello-nf-core/work
projectDir : /workspaces/training/hello-nf-core/core-hello
userName : root
profile : test,docker
configFiles : /workspaces/training/hello-nf-core/core-hello/nextflow.config
!! Only displaying parameters that differ from the pipeline defaults !!
------------------------------------------------------
executor > local (1)
[ed/727b7e] CORE_HELLO:HELLO:sayHello (3) [100%] 3 of 3 ✔
[45/bb6096] CORE_HELLO:HELLO:convertToUpper (3) [100%] 3 of 3 ✔
[81/7e2e34] CORE_HELLO:HELLO:collectGreetings [100%] 1 of 1 ✔
[96/9442a1] CORE_HELLO:HELLO:cowpy [100%] 1 of 1 ✔
-[core/hello] Pipeline completed successfully-
जैसा कि तुम देख सकते हो, initialisation subworkflow की बदौलत शुरुआत में typical nf-core summary produce हुआ, और प्रत्येक module के लिए lines अब पूर्ण PIPELINE:WORKFLOW:module नाम दिखाती हैं।
5.5. Pipeline outputs खोजें¶
अब सवाल है: pipeline के outputs कहाँ हैं? और जवाब काफी दिलचस्प है: अब results खोजने के लिए दो अलग-अलग जगहें हैं।
जैसा कि तुम्हें पहले से याद हो सकता है, नए बनाए गए workflow का पहला run core-hello-results/ नाम की एक डायरेक्टरी produce करता है जिसमें विभिन्न execution reports और metadata होते हैं।
डायरेक्टरी सामग्री
core-hello-results
└── pipeline_info
├── execution_report_2025-11-21_04-47-18.html
├── execution_report_2025-11-21_07-29-37.html
├── execution_timeline_2025-11-21_04-47-18.html
├── execution_timeline_2025-11-21_07-29-37.html
├── execution_trace_2025-11-21_04-47-18.txt
├── execution_trace_2025-11-21_07-29-37.txt
├── hello_software_versions.yml
├── params_2025-11-21_04-47-13.json
├── params_2025-11-21_07-29-41.json
├── pipeline_dag_2025-11-21_04-47-18.html
└── pipeline_dag_2025-11-21_07-29-37.html
1 directory, 12 files
तुम देख सकते हो कि पहले run से मिले reports के अलावा हमें execution reports का एक और set मिला, जब workflow अभी भी सिर्फ एक placeholder था। इस बार तुम अपेक्षानुसार चलाए गए सभी tasks देखते हो।
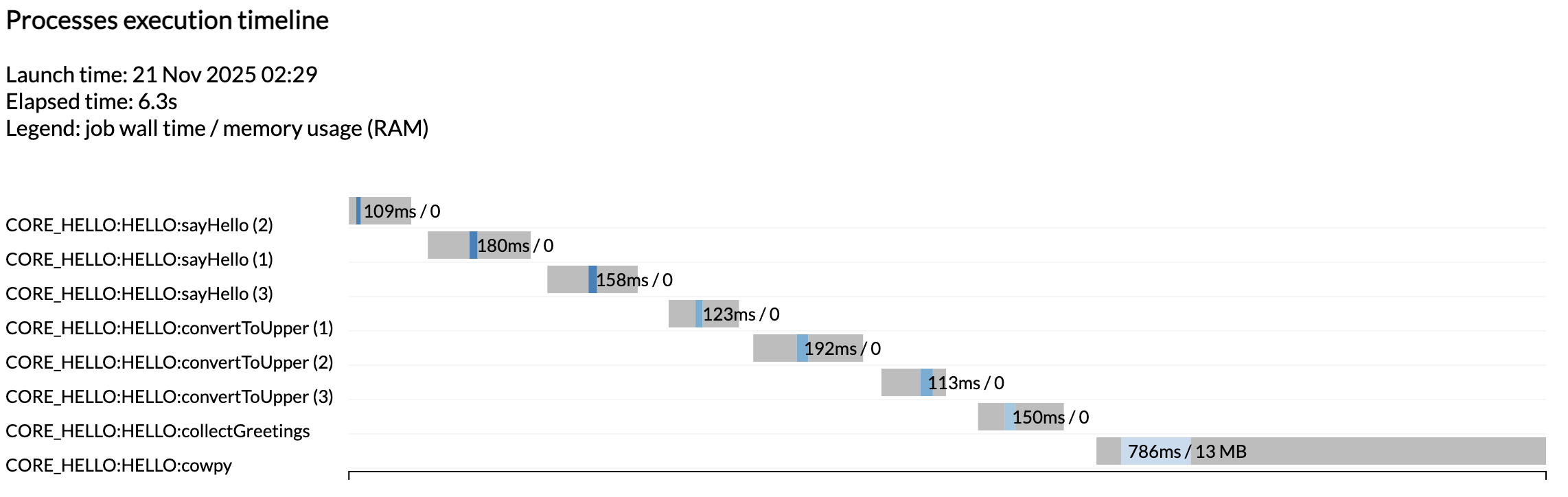
नोट
एक बार फिर tasks parallel में नहीं चलाए गए क्योंकि हम Github Codespaces में एक minimalist machine पर चला रहे हैं। इन्हें parallel में चलते हुए देखने के लिए, अपने codespace का CPU allocation और test configuration में resource limits बढ़ाने का प्रयास करो।
यह बहुत अच्छा है, लेकिन हमारे actual pipeline results वहाँ नहीं हैं!
यहाँ क्या हुआ: हमने modules में ही कुछ भी नहीं बदला, इसलिए module-level publishDir directives द्वारा handle किए जाने वाले outputs अभी भी original pipeline में specified results डायरेक्टरी में जा रहे हैं।
डायरेक्टरी सामग्री
results
├── Bonjour-output.txt
├── COLLECTED-test-batch-output.txt
├── COLLECTED-test-output.txt
├── cowpy-COLLECTED-test-batch-output.txt
├── cowpy-COLLECTED-test-output.txt
├── Hello-output.txt
├── Hola-output.txt
├── UPPER-Bonjour-output.txt
├── UPPER-Hello-output.txt
└── UPPER-Hola-output.txt
0 directories, 10 files
आह, वे वहाँ हैं, original Hello pipeline के पहले के runs के outputs के साथ मिश्रित।
यदि हम चाहते हैं कि वे demo pipeline के outputs की तरह अच्छी तरह से organize हों, तो हमें outputs को publish करने का तरीका बदलना होगा। इस training course में बाद में हम तुम्हें दिखाएंगे कि यह कैसे किया जाता है।
और यह रहा! यह original pipeline के समान परिणाम प्राप्त करने के लिए बहुत काम जैसा लग सकता है, लेकिन तुम्हें स्वचालित रूप से generate होने वाले वे सभी बढ़िया reports मिलते हैं, और अब तुम्हारे पास nf-core की अतिरिक्त सुविधाओं का लाभ उठाने के लिए एक ठोस आधार है, जिसमें input validation और कुछ उपयोगी metadata handling क्षमताएं शामिल हैं जिन्हें हम बाद के section में cover करेंगे।
सारांश¶
तुम जानते हो कि nf-core template का उपयोग करके एक regular Nextflow pipeline को nf-core style pipeline में कैसे convert किया जाए। इसके भाग के रूप में, तुमने सीखा कि एक workflow को composable कैसे बनाया जाए, और custom nf-core style pipeline विकसित करते समय nf-core template के उन elements को कैसे पहचाना जाए जिन्हें सबसे अधिक अनुकूलित करने की आवश्यकता होती है।
आगे क्या है?¶
एक ब्रेक लो, यह कठिन काम था! जब तुम तैयार हो, तो nf-core/modules repository से community-maintained modules का लाभ उठाना सीखने के लिए भाग 3: एक nf-core module का उपयोग करें पर आगे बढ़ो।