Parte 2: Riscrivere Hello per nf-core¶
Traduzione assistita da IA - scopri di più e suggerisci miglioramenti
In questa seconda parte del corso di formazione Hello nf-core, vi mostriamo come creare una versione compatibile con nf-core della pipeline prodotta dal corso per principianti Hello Nextflow.
Lo faremo in due fasi: prima utilizzeremo gli strumenti nf-core per creare uno scaffold della pipeline, poi innesteremo il codice della pipeline 'regolare' esistente sullo scaffold.
Se non avete familiarità con la pipeline Hello o potreste aver bisogno di un ripasso, consultate questa pagina informativa.
Suggerimento
Questa parte del corso introdurrà due importanti meccanismi di Nextflow che non sono trattati nel corso introduttivo Hello Nextflow: meta maps e workflows of workflows, entrambi trattati in dettaglio nelle Side Quest collegate.
Le istruzioni seguenti includono le informazioni essenziali necessarie per capire come vengono utilizzati nel contesto nf-core, ma può essere molto da assimilare tutto in una volta. Se avete il tempo, vi consigliamo di lavorare prima sulle due Side Quest (in qualsiasi ordine):
Nota
Assicuratevi di trovarvi nella directory hello-nf-core nel vostro terminale.
1. Esaminare la struttura del codice della pipeline¶
Il progetto nf-core impone linee guida rigorose su come le pipeline sono strutturate e su come il codice è organizzato, configurato e documentato.
Prima di affrontare il nostro progetto di creazione della pipeline, dobbiamo comprendere quella struttura e organizzazione.
Quindi diamo un'occhiata a come il codice della pipeline è organizzato nel repository nf-core/demo, utilizzando il symlink pipelines che abbiamo creato nella Parte 1.
Come promemoria, potete usare tree o il file explorer per trovare e aprire la directory nf-core/demo.
Contenuto della directory
pipelines/nf-core/demo
├── assets
├── CHANGELOG.md
├── CITATIONS.md
├── CODE_OF_CONDUCT.md
├── conf
├── docs
├── LICENSE
├── main.nf
├── modules
├── modules.json
├── nextflow.config
├── nextflow_schema.json
├── nf-test.config
├── README.md
├── ro-crate-metadata.json
├── subworkflows
├── tests
├── tower.yml
└── workflows
Per ora ci concentreremo specificamente sui componenti del codice della pipeline (main.nf, workflows, subworkflows, modules) e su come si relazionano tra loro.
1.1. Struttura modulare dei flussi di lavoro nf-core¶
L'organizzazione standard del codice delle pipeline nf-core segue una struttura modulare progettata per massimizzare il riutilizzo del codice, come introdotto in Hello Modules, Parte 4 del corso Hello Nextflow, sebbene in vero stile nf-core, questo sia implementato con un po' di complessità aggiuntiva. In particolare, le pipeline nf-core fanno un uso abbondante di subworkflow, ovvero script di flusso di lavoro importati da un flusso di lavoro genitore.
Può sembrare un po' astratto, quindi vediamo come viene utilizzato in pratica nella pipeline nf-core/demo.
Se guardate dentro il file main.nf, vedrete che importa un flusso di lavoro chiamato DEMO da workflows/demo.nf, insieme ad alcuni moduli e subworkflow.
Ecco come appaiono le relazioni tra i componenti del codice rilevanti:
Il flusso di lavoro senza nome in main.nf è chiamato script entrypoint. Funge da wrapper per due tipi di flussi di lavoro annidati: il flusso di lavoro DEMO contenente la logica di analisi effettiva, situato in workflows/demo.nf, e un insieme di flussi di lavoro di housekeeping situati sotto subworkflows/.
Il flusso di lavoro demo.nf si avvale di moduli situati sotto modules/; questi contengono i processi che eseguiranno i passi di analisi effettivi.
Nota
I subworkflow non sono limitati alle funzioni di housekeeping e possono utilizzare moduli di processo.
La pipeline nf-core/demo mostrata qui è sul lato più semplice dello spettro, ma altre pipeline nf-core (come nf-core/rnaseq) utilizzano subworkflow coinvolti nell'analisi effettiva.
Ora esaminiamo questi componenti in dettaglio.
1.2. Lo script entrypoint: main.nf¶
Lo script main.nf è l'entrypoint da cui Nextflow parte quando eseguiamo nextflow run nf-core/demo.
Ciò significa che quando eseguite nextflow run nf-core/demo per eseguire la pipeline, Nextflow trova ed esegue automaticamente lo script main.nf.
Questo funziona per qualsiasi pipeline Nextflow che segue questa denominazione e struttura convenzionale, non solo per le pipeline nf-core.
Utilizzare uno script entrypoint rende facile eseguire subworkflow di 'housekeeping' standardizzati prima e dopo l'esecuzione dello script di analisi effettivo. Li esamineremo dopo aver rivisto il flusso di lavoro di analisi effettivo e i suoi moduli.
1.3. Lo script di analisi: workflows/demo.nf¶
Il flusso di lavoro workflows/demo.nf è dove è memorizzata la logica centrale della pipeline.
È strutturato in modo simile a un normale flusso di lavoro Nextflow, tranne per il fatto che è progettato per essere chiamato da un flusso di lavoro genitore, il che richiede alcune funzionalità aggiuntive.
Tratteremo le differenze rilevanti nella prossima parte di questo corso, quando affronteremo la conversione della semplice pipeline Hello da Hello Nextflow in una forma compatibile con nf-core.
Il flusso di lavoro demo.nf si avvale di moduli situati sotto modules/, che esamineremo di seguito.
Nota
Alcuni flussi di lavoro di analisi nf-core mostrano livelli aggiuntivi di annidamento chiamando subworkflow di livello inferiore. Questo viene utilizzato principalmente per raggruppare due o più moduli comunemente usati insieme in segmenti di pipeline facilmente riutilizzabili. Potete vedere alcuni esempi sfogliando i subworkflow nf-core disponibili sul sito web nf-core.
Quando lo script di analisi utilizza subworkflow, questi sono memorizzati sotto la directory subworkflows/.
1.4. I moduli¶
I moduli sono dove vive il codice dei processi, come descritto nella Parte 4 del corso di formazione Hello Nextflow.
Nel progetto nf-core, i moduli sono organizzati utilizzando una struttura annidata a più livelli che riflette sia la loro origine che il loro contenuto.
Al livello superiore, i moduli sono differenziati come nf-core o local (non parte del progetto nf-core), e poi ulteriormente collocati in una directory denominata in base agli strumenti che racchiudono.
Se lo strumento appartiene a un toolkit (ovvero un pacchetto contenente più strumenti), c'è un livello di directory intermedio denominato in base al toolkit.
Potete vedere questo applicato in pratica ai moduli della pipeline nf-core/demo:
Contenuto della directory
Qui vedete che i moduli fastqc e multiqc si trovano al livello superiore all'interno dei moduli nf-core, mentre il modulo trim si trova sotto il toolkit a cui appartiene, seqtk.
In questo caso non ci sono moduli local.
Il file del codice del modulo che descrive il processo è sempre chiamato main.nf, ed è accompagnato da test e file .yml che ignoreremo per ora.
Nel complesso, il flusso di lavoro entrypoint, il flusso di lavoro di analisi e i moduli sono sufficienti per eseguire le parti 'interessanti' della pipeline. Tuttavia, sappiamo che ci sono anche subworkflow di housekeeping, quindi esaminiamoli ora.
1.5. I subworkflow di housekeeping¶
Come i moduli, i subworkflow sono differenziati in directory local e nf-core, e ogni subworkflow ha la propria struttura di directory annidata con il proprio script main.nf, test e file .yml.
Contenuto della directory
pipelines/nf-core/demo/subworkflows
├── local
│ └── utils_nfcore_demo_pipeline
│ └── main.nf
└── nf-core
├── utils_nextflow_pipeline
│ ├── main.nf
│ ├── meta.yml
│ └── tests
├── utils_nfcore_pipeline
│ ├── main.nf
│ ├── meta.yml
│ └── tests
└── utils_nfschema_plugin
├── main.nf
├── meta.yml
└── tests
9 directories, 7 files
Come notato sopra, la pipeline nf-core/demo non include subworkflow specifici per l'analisi, quindi tutti i subworkflow che vediamo qui sono i cosiddetti flussi di lavoro di 'housekeeping' o 'utility', come indicato dal prefisso utils_ nei loro nomi.
Questi subworkflow sono ciò che produce il bell'header nf-core nell'output della console, tra le altre funzioni accessorie.
Suggerimento
Oltre al loro schema di denominazione, un'altra indicazione che questi subworkflow non svolgono alcuna funzione veramente correlata all'analisi è che non chiamano alcun processo.
Questo completa la panoramica dei componenti principali del codice che costituiscono la pipeline nf-core/demo.
Takeaway¶
Ora avete una comprensione di alto livello della struttura modulare delle pipeline nf-core.
Cosa c'è dopo?¶
Creare uno scaffold di pipeline utilizzando gli strumenti nf-core.
2. Creare un nuovo progetto pipeline¶
Come avete visto, le pipeline nf-core seguono una struttura standardizzata con molti file accessori. Creare tutto ciò da zero sarebbe molto tedioso, quindi la comunità nf-core ha sviluppato strumenti per farlo invece da un template, per avviare il processo.
2.1. Eseguire lo strumento di creazione pipeline basato su template¶
Iniziamo creando una nuova pipeline con il comando nf-core pipelines create.
Questo creerà un nuovo scaffold di pipeline utilizzando il template base nf-core, personalizzato con un nome, una descrizione e un autore della pipeline.
L'esecuzione di questo comando aprirà un'interfaccia utente testuale (TUI) per la creazione della pipeline:
Questa TUI vi chiederà di fornire informazioni di base sulla vostra pipeline e vi offrirà una scelta di funzionalità da includere o escludere nello scaffold della pipeline.
- Nella schermata di benvenuto, cliccate su Let's go!.
- Nella schermata
Choose pipeline type, cliccate su Custom. - Inserite i dettagli della vostra pipeline come segue (sostituendo
< IL VOSTRO NOME >con il vostro nome), quindi cliccate su Next.
[ ] GitHub organisation: core
[ ] Workflow name: hello
[ ] A short description of your pipeline: A basic nf-core style version of Hello Nextflow
[ ] Name of the main author(s): < YOUR NAME >
- Nella schermata Template features, impostate
Toggle all featuressu off, quindi abilitate selettivamente i seguenti. Controllate le vostre selezioni e cliccate su Continue.
[ ] Add testing profiles
[ ] Use nf-core components
[ ] Use nf-schema
[ ] Add configuration files
[ ] Add documentation
- Nella schermata
Final details, cliccate su Finish. Attendete che la pipeline venga creata, quindi cliccate su Continue. - Nella schermata Create GitHub repository, cliccate su Finish without creating a repo. Questo mostrerà le istruzioni per creare successivamente un repository GitHub. Ignoratele e cliccate su Close.
Una volta chiusa la TUI, dovreste vedere il seguente output nella console.
Output del comando
Non c'è una conferma esplicita nell'output della console che la creazione della pipeline abbia funzionato, ma dovreste vedere una nuova directory chiamata core-hello.
Visualizzate i contenuti della nuova directory per vedere quanto lavoro vi siete risparmiati utilizzando il template.
Contenuto della directory
core-hello/
├── README.md
├── assets
│ ├── samplesheet.csv
│ └── schema_input.json
├── conf
│ ├── base.config
│ ├── modules.config
│ ├── test.config
│ └── test_full.config
├── docs
│ ├── README.md
│ ├── output.md
│ └── usage.md
├── main.nf
├── modules.json
├── nextflow.config
├── nextflow_schema.json
├── subworkflows
│ ├── local
│ │ └── utils_nfcore_hello_pipeline
│ │ └── main.nf
│ └── nf-core
│ ├── utils_nextflow_pipeline
│ │ ├── main.nf
│ │ ├── meta.yml
│ │ └── tests
│ │ ├── main.function.nf.test
│ │ ├── main.function.nf.test.snap
│ │ ├── main.workflow.nf.test
│ │ └── nextflow.config
│ ├── utils_nfcore_pipeline
│ │ ├── main.nf
│ │ ├── meta.yml
│ │ └── tests
│ │ ├── main.function.nf.test
│ │ ├── main.function.nf.test.snap
│ │ ├── main.workflow.nf.test
│ │ ├── main.workflow.nf.test.snap
│ │ └── nextflow.config
│ └── utils_nfschema_plugin
│ ├── main.nf
│ ├── meta.yml
│ └── tests
│ ├── main.nf.test
│ ├── nextflow.config
│ └── nextflow_schema.json
└── workflows
└── hello.nf
15 directories, 34 files
Sono molti file! Non preoccupatevi se vi sentite ancora un po' spaesati; percorreremo insieme le parti importanti a breve, e poi passo dopo passo nel resto del corso.
Nel complesso, dovrebbe sembrare simile alla struttura del codice che abbiamo osservato per la pipeline nf-core/demo, tranne per il fatto che qui non c'è una directory modules.
2.2. Testare che lo scaffold sia funzionale¶
Che ci crediate o no, anche se non avete ancora aggiunto alcun modulo per farle svolgere un lavoro reale, lo scaffold della pipeline può effettivamente essere eseguito utilizzando il profilo test, nello stesso modo in cui abbiamo eseguito la pipeline nf-core/demo.
Output del comando
N E X T F L O W ~ version 25.10.4
Launching `./core-hello/main.nf` [scruffy_marconi] DSL2 - revision: b9e9b3b8de
Downloading plugin nf-schema@2.5.1
Input/output options
input : https://raw.githubusercontent.com/nf-core/test-datasets/viralrecon/samplesheet/samplesheet_test_illumina_amplicon.csv
outdir : core-hello-results
Institutional config options
config_profile_name : Test profile
config_profile_description: Minimal test dataset to check pipeline function
Generic options
trace_report_suffix : 2025-11-21_04-47-18
Core Nextflow options
runName : scruffy_marconi
containerEngine : docker
launchDir : /workspaces/training/hello-nf-core
workDir : /workspaces/training/hello-nf-core/work
projectDir : /workspaces/training/hello-nf-core/core-hello
userName : root
profile : docker,test
configFiles : /workspaces/training/hello-nf-core/core-hello/nextflow.config
!! Only displaying parameters that differ from the pipeline defaults !!
------------------------------------------------------
-[core/hello] Pipeline completed successfully-
Questo vi mostra che tutto il cablaggio di base è a posto. Quindi, dove sono gli output? Ce ne sono?
In effetti, è stata creata una nuova directory di risultati chiamata core-hello-results contenente i report di esecuzione standard:
Contenuto della directory
core-hello-results
└── pipeline_info
├── execution_report_2025-11-21_04-47-18.html
├── execution_timeline_2025-11-21_04-47-18.html
├── execution_trace_2025-11-21_04-47-18.txt
├── hello_software_versions.yml
├── params_2025-11-21_04-47-18.json
└── pipeline_dag_2025-11-21_04-47-18.html
1 directory, 6 files
Potete dare un'occhiata ai report per vedere cosa è stato eseguito, e la risposta è: niente del tutto!

Diamo un'occhiata più da vicino a cosa c'è effettivamente nel codice.
2.3. Esaminare la struttura dello scaffold¶
Se ricordate la struttura della pipeline nf-core/demo, c'era un file main.nf contenente un flusso di lavoro entrypoint che racchiudeva il flusso di lavoro DEMO.
Ora se aprite il file main.nf nel vostro progetto appena creato, vedrete che importa un flusso di lavoro chiamato HELLO da workflows/hello.nf.
Questo è l'equivalente diretto del flusso di lavoro DEMO, anche se al momento è solo un placeholder.
E di conseguenza, questa è la struttura complessiva dello scaffold della pipeline:
Questo dovrebbe ricordarvi la struttura della pipeline nf-core/demo!
L'unica vera differenza è che il flusso di lavoro DEMO includeva processi dai moduli.
Qui, il flusso di lavoro equivalente HELLO non include ancora alcun processo.
Diamo un'occhiata più da vicino.
2.4. Esaminare il workflow placeholder¶
Questo funge da placeholder per il nostro flusso di lavoro di analisi, con alcune funzionalità nf-core già in atto.
Rispetto a un flusso di lavoro Nextflow di base come quello sviluppato in Hello Nextflow, noterete alcune cose nuove qui (righe evidenziate sopra):
- Il blocco workflow ha un nome
- Gli input del flusso di lavoro sono dichiarati utilizzando la parola chiave
take:e la costruzione del canale viene spostata al flusso di lavoro genitore - Il contenuto del flusso di lavoro è posizionato all'interno di un blocco
main: - Gli output sono dichiarati utilizzando la parola chiave
emit:
Queste sono funzionalità opzionali di Nextflow che rendono il flusso di lavoro componibile, il che significa che può essere richiamato dall'interno di un altro flusso di lavoro.
Il blocco Channel.topic
Potreste aver notato il blocco def topic_versions = Channel.topic("versions") che inizia alla riga 17.
Si tratta di codice di housekeeping standard che raccoglie automaticamente le informazioni sulla versione del software da tutti i moduli.
nf-core sta introducendo questo meccanismo in tutte le pipeline nel 2026, quindi lo vedrete in tutte le nuove pipeline da ora in avanti.
La Parte 4 di questo corso spiega come funziona in dettaglio.
Dovremo collegare la logica pertinente dal nostro flusso di lavoro di interesse in quella struttura.
Takeaway¶
Ora sapete come creare uno scaffold di pipeline utilizzando gli strumenti nf-core e come confrontarlo con la struttura della pipeline demo.
Cosa c'è dopo?¶
Imparare come rendere un semplice flusso di lavoro componibile come preludio a renderlo compatibile con nf-core.
3. Rendere componibile il workflow Hello Nextflow originale¶
Ora è il momento di mettersi al lavoro per integrare il nostro flusso di lavoro nello scaffold nf-core.
Come promemoria, stiamo lavorando con il flusso di lavoro presentato nel nostro corso di formazione Hello Nextflow. Quel flusso di lavoro è stato scritto come un semplice flusso di lavoro senza nome che può essere eseguito autonomamente.
Per mappare chiaramente quali parti del flusso di lavoro originale dovrebbero andare dove nello scaffold nf-core, inizieremo trasformando il flusso di lavoro Hello originale in un flusso di lavoro componibile che può essere eseguito dall'interno di un flusso di lavoro genitore, come richiede il template nf-core.
Questo è ciò che stiamo cercando di costruire in questo momento:
In sostanza, vogliamo imitare la struttura modulare dello scaffold nf-core, ma con meno complessità per cominciare.
Vi forniamo una copia pulita e completamente funzionale del workflow Hello Nextflow completato nella directory original-hello insieme ai suoi moduli e al file CSV predefinito che si aspetta di utilizzare come input.
Contenuto della directory
Sentitevi liberi di eseguirla per assicurarvi che funzioni:
Output del comando
Se funziona, siete pronti per iniziare.
3.1. Modificare il workflow Hello originale¶
Apriamo il file workflow hello.nf per ispezionare il codice, che è mostrato per intero di seguito (senza contare i processi, che sono nei moduli):
Come potete vedere, questo flusso di lavoro è stato scritto come un semplice flusso di lavoro senza nome che può essere eseguito autonomamente. Per renderlo componibile, apporteremo le seguenti modifiche:
- Nominare il flusso di lavoro
- Sostituire la costruzione del canale con
take: - Prefare le operazioni del flusso di lavoro con
main: - Aggiungere la dichiarazione
emit:
Esaminiamo le modifiche necessarie una per una.
3.1.1. Nominare il workflow¶
Prima di tutto, diamo un nome al flusso di lavoro così possiamo fare riferimento ad esso da un flusso di lavoro genitore.
Le stesse convenzioni si applicano ai nomi dei flussi di lavoro come ai nomi dei moduli.
3.1.2. Sostituire la costruzione del canale con take¶
Ora, sostituite la costruzione del canale con una semplice dichiarazione take che dichiara gli input attesi.
Questo lascia i dettagli di come vengono forniti gli input al flusso di lavoro genitore.
Mentre ci siamo, possiamo anche commentare la riga params.greeting = 'greetings.csv'
Nota
Se avete installato l'estensione del language server di Nextflow, il controllo della sintassi evidenzierà il vostro codice con sottolineature rosse ondulate.
Questo perché se inserite una dichiarazione take:, dovete anche avere un main:.
Lo aggiungeremo nel prossimo passaggio.
3.1.3. Prefare le operazioni del workflow con la dichiarazione main¶
Successivamente, aggiungete una dichiarazione main prima del resto delle operazioni chiamate nel corpo del flusso di lavoro.
Questo sostanzialmente dice 'questo è ciò che questo flusso di lavoro fa'.
3.1.4. Aggiungere la dichiarazione emit¶
Infine, aggiungete una dichiarazione emit che dichiara quali sono gli output finali del flusso di lavoro.
Questa è un'aggiunta completamente nuova al codice rispetto al flusso di lavoro originale.
3.1.5. Riepilogo delle modifiche completate¶
Se avete effettuato tutte le modifiche come descritto, il vostro flusso di lavoro dovrebbe ora apparire così:
Questo descrive tutto ciò di cui Nextflow ha bisogno TRANNE cosa alimentare nel canale di input. Ciò sarà definito nel flusso di lavoro genitore, chiamato anche flusso di lavoro entrypoint.
3.2. Creare un workflow entrypoint fittizio¶
Prima di integrare il nostro flusso di lavoro componibile nello scaffold complesso nf-core, verifichiamo che funzioni correttamente. Possiamo creare un semplice flusso di lavoro entrypoint fittizio per testare il flusso di lavoro componibile in isolamento.
Create un file vuoto chiamato main.nf nella stessa directory original-hello.
Copiate il seguente codice nel file main.nf.
Ci sono due osservazioni importanti da fare qui:
- La sintassi per chiamare il flusso di lavoro importato è essenzialmente la stessa della sintassi per chiamare i moduli.
- Tutto ciò che è correlato al trasferimento degli input nel flusso di lavoro (parametro di input e costruzione del canale) è ora dichiarato in questo flusso di lavoro genitore.
Nota
Nominare il file del flusso di lavoro entrypoint main.nf è una convenzione, non un requisito.
Se seguite questa convenzione, potete omettere di specificare il nome del file del flusso di lavoro nel vostro comando nextflow run.
Nextflow cercherà automaticamente un file chiamato main.nf nella directory di esecuzione.
Tuttavia, potete nominare il file del flusso di lavoro entrypoint in altro modo se preferite.
In tal caso, assicuratevi di specificare il nome del file del flusso di lavoro nel vostro comando nextflow run.
3.3. Testare che il workflow venga eseguito¶
Abbiamo finalmente tutti i pezzi di cui abbiamo bisogno per verificare che il flusso di lavoro componibile funzioni. Eseguiamolo!
Qui vedete il vantaggio di utilizzare la convenzione di denominazione main.nf.
Se avessimo nominato il flusso di lavoro entrypoint something_else.nf, avremmo dovuto fare nextflow run original-hello/something_else.nf.
Se avete effettuato tutte le modifiche correttamente, questo dovrebbe essere eseguito fino al completamento.
Output del comando
N E X T F L O W ~ version 25.10.4
Launching `original-hello/main.nf` [friendly_wright] DSL2 - revision: 1ecd2d9c0a
executor > local (8)
[24/c6c0d8] HELLO:sayHello (3) | 3 of 3 ✔
[dc/721042] HELLO:convertToUpper (3) | 3 of 3 ✔
[48/5ab2df] HELLO:collectGreetings | 1 of 1 ✔
[e3/693b7e] HELLO:cowpy | 1 of 1 ✔
Output: /workspaces/training/hello-nf-core/work/e3/693b7e48dc119d0c54543e0634c2e7/cowpy-COLLECTED-test-batch-output.txt
Questo significa che abbiamo aggiornato con successo il nostro flusso di lavoro HELLO per essere componibile.
Takeaway¶
Sapete come rendere un flusso di lavoro componibile dandogli un nome e aggiungendo dichiarazioni take, main ed emit, e come chiamarlo da un flusso di lavoro entrypoint.
Cosa c'è dopo?¶
Imparare come innestare un flusso di lavoro componibile di base sullo scaffold nf-core.
4. Adattare la logica del workflow aggiornato nel workflow placeholder¶
Ora che abbiamo verificato che il nostro flusso di lavoro componibile funziona correttamente, torniamo allo scaffold della pipeline nf-core che abbiamo creato nella sezione 1. Vogliamo integrare il flusso di lavoro componibile che abbiamo appena sviluppato nella struttura del template nf-core, quindi il risultato finale dovrebbe apparire così.
Quindi come facciamo a farlo accadere? Diamo un'occhiata al contenuto attuale del flusso di lavoro HELLO in core-hello/workflows/hello.nf (lo scaffold nf-core).
Le righe evidenziate definiscono la struttura del flusso di lavoro componibile: workflow HELLO {, take:, main: ed emit:.
Il grande blocco tra le righe 17–34 è più sostanziale: gestisce la cattura delle versioni del software utilizzando i topic channel, un meccanismo che nf-core sta introducendo in tutte le pipeline nel 2026.
Lo spiegheremo nella Parte 4; per ora, trattatelo come codice standard che potete lasciare invariato.
Dobbiamo aggiungere il codice pertinente dalla versione componibile del flusso di lavoro originale che abbiamo sviluppato nella sezione 2.
Affronteremo questo nelle seguenti fasi:
- Copiare i moduli e configurare le importazioni dei moduli
- Lasciare la dichiarazione
takecosì com'è - Aggiungere la logica del flusso di lavoro al blocco
main - Aggiornare il blocco
emit
Nota
Ignoreremo il blocco di cattura delle versioni per questo primo passaggio. La Parte 4 spiega come funziona.
4.1. Copiare i moduli e configurare le importazioni dei moduli¶
I quattro processi del nostro flusso di lavoro Hello Nextflow sono memorizzati come moduli in original-hello/modules/.
Dobbiamo copiare quei moduli nella struttura del progetto nf-core (sotto core-hello/modules/local/) e aggiungere dichiarazioni di importazione al file del flusso di lavoro nf-core.
Prima copiamo i file dei moduli da original-hello/ a core-hello/:
Ora dovreste vedere la directory dei moduli elencata sotto core-hello/.
Contenuto della directory
Ora configuriamo le dichiarazioni di importazione dei moduli.
Queste erano le dichiarazioni di importazione nel flusso di lavoro original-hello/hello.nf:
| original-hello/hello.nf | |
|---|---|
Aprite il file core-hello/workflows/hello.nf e trasponate quelle dichiarazioni di importazione in esso come mostrato di seguito.
Altre due osservazioni interessanti qui:
- Abbiamo adattato la formattazione delle dichiarazioni di importazione per seguire la convenzione di stile nf-core.
- Abbiamo aggiornato i percorsi relativi ai moduli per riflettere che ora sono memorizzati a un livello diverso di annidamento.
4.2. Lasciare la dichiarazione take così com'è¶
Il progetto nf-core ha molte funzionalità pre-costruite intorno al concetto di samplesheet, che è tipicamente un file CSV contenente dati in colonne.
Poiché è essenzialmente ciò che è il nostro file greetings.csv, manterremo l'attuale dichiarazione take così com'è, e aggiorneremo semplicemente il nome del canale di input nel prossimo passaggio.
| core-hello/workflows/hello.nf | |
|---|---|
La gestione dell'input sarà fatta a monte di questo flusso di lavoro (non in questo file di codice).
4.3. Aggiungere la logica del workflow al blocco main¶
Ora che i nostri moduli sono disponibili per il flusso di lavoro, possiamo collegare la logica del flusso di lavoro nel blocco main.
Come promemoria, questo è il codice pertinente nel flusso di lavoro originale, che non è cambiato molto quando l'abbiamo reso componibile (abbiamo solo aggiunto la riga main:):
Dobbiamo copiare il codice che viene dopo main: nella nuova versione del flusso di lavoro.
C'è già del codice lì che ha a che fare con la cattura delle versioni degli strumenti che vengono eseguiti dal flusso di lavoro. Lo lasceremo in pace per ora (ci occuperemo delle versioni degli strumenti più tardi).
Manterremo l'inizializzazione ch_versions = channel.empty() in alto, quindi inseriremo la nostra logica del flusso di lavoro, mantenendo il codice di raccolta delle versioni alla fine.
Questo ordinamento ha senso perché in una pipeline reale, i processi emetterebbero informazioni sulla versione che verrebbero aggiunte al canale ch_versions mentre il flusso di lavoro viene eseguito.
Noterete che abbiamo anche aggiunto una riga vuota prima di main: per rendere il codice più leggibile.
Sembra ottimo, ma dobbiamo ancora aggiornare il nome del canale che stiamo passando al processo sayHello() da greeting_ch a ch_samplesheet come mostrato di seguito, per corrispondere a ciò che è scritto sotto la parola chiave take:.
Ora la logica del flusso di lavoro è correttamente collegata.
4.4. Aggiornare il blocco emit¶
Infine, dobbiamo aggiornare il blocco emit per includere la dichiarazione degli output finali del flusso di lavoro.
Questo conclude le modifiche che dobbiamo apportare al flusso di lavoro HELLO stesso. A questo punto, abbiamo raggiunto la struttura complessiva del codice che ci eravamo proposti di implementare.
Takeaway¶
Sapete come adattare i pezzi principali di un flusso di lavoro componibile in un workflow placeholder nf-core.
Cosa c'è dopo?¶
Imparare come adattare la gestione degli input nello scaffold della pipeline nf-core.
5. Adattare la gestione degli input¶
Ora che abbiamo integrato con successo la nostra logica del flusso di lavoro nello scaffold nf-core, dobbiamo affrontare un altro pezzo critico: assicurarci che i nostri dati di input siano elaborati correttamente.
Il template nf-core viene fornito con una gestione degli input sofisticata progettata per dataset genomici complessi, quindi dobbiamo adattarla per funzionare con il nostro file greetings.csv più semplice.
5.1. Identificare dove vengono gestiti gli input¶
Il primo passo è capire dove viene eseguita la gestione degli input.
Potreste ricordare che quando abbiamo riscritto il flusso di lavoro Hello Nextflow per renderlo componibile, abbiamo spostato la dichiarazione del parametro di input di un livello verso l'alto, nel flusso di lavoro entrypoint main.nf.
Quindi diamo un'occhiata al flusso di lavoro entrypoint main.nf di livello superiore che è stato creato come parte dello scaffold della pipeline:
Il progetto nf-core fa un uso intensivo di subworkflow annidati, quindi questa parte può risultare un po' confusa al primo approccio.
Ciò che conta qui è che ci sono due flussi di lavoro definiti:
CORE_HELLOè un wrapper sottile per l'esecuzione del flusso di lavoro HELLO che abbiamo appena finito di adattare incore-hello/workflows/hello.nf.- Un flusso di lavoro senza nome che chiama
CORE_HELLOcosì come altri due subworkflow,PIPELINE_INITIALISATIONePIPELINE_COMPLETION.
Ecco un diagramma di come si relazionano tra loro:
Importante, non possiamo trovare alcun codice che costruisce un canale di input a questo livello, solo riferimenti a un samplesheet fornito tramite il parametro --input.
Un po' di ricerca rivela che la gestione degli input è eseguita dal subworkflow PIPELINE_INITIALISATION, appropriatamente, che è importato da core-hello/subworkflows/local/utils_nfcore_hello_pipeline/main.nf.
Se apriamo quel file e scorriamo verso il basso, arriviamo a questo blocco di codice:
Questa è la fabbrica di canali che analizza il samplesheet e lo passa in una forma pronta per essere consumata dal flusso di lavoro HELLO.
Nota
La sintassi sopra è un po' diversa da quella che abbiamo usato in precedenza, ma fondamentalmente questo:
è equivalente a questo:
Questo codice coinvolge alcuni passaggi di analisi e validazione che sono altamente specifici per il samplesheet di esempio incluso con il template della pipeline nf-core, che al momento della scrittura è molto specifico del dominio e non adatto per il nostro progetto di pipeline semplice.
5.2. Sostituire il codice del canale di input del template¶
La buona notizia è che le esigenze della nostra pipeline sono molto più semplici, quindi possiamo sostituire tutto ciò con il codice di costruzione del canale che abbiamo sviluppato nel flusso di lavoro Hello Nextflow originale.
Come promemoria, ecco come appariva la costruzione del canale (come visto nella directory delle soluzioni):
| solutions/composable-hello/main.nf | |
|---|---|
Quindi dobbiamo solo collegarlo nel flusso di lavoro di inizializzazione, con modifiche minori: aggiorniamo il nome del canale da greeting_ch a ch_samplesheet, e il nome del parametro da params.greeting a params.input (vedi riga evidenziata).
| core-hello/subworkflows/local/utils_nfcore_hello_pipeline/main.nf | |
|---|---|
Questo completa le modifiche di cui abbiamo bisogno per far funzionare l'elaborazione degli input.
Nella sua forma attuale, questo non ci permetterà di sfruttare le capacità integrate di nf-core per la validazione dello schema, ma possiamo aggiungere ciò in seguito. Per ora, ci stiamo concentrando nel mantenerlo il più semplice possibile per arrivare a qualcosa che possiamo eseguire con successo sui dati di test.
5.3. Aggiornare il profilo test¶
Parlando di dati e parametri di test, aggiorniamo il profilo test per questa pipeline per utilizzare il mini-samplesheet greetings.csv invece del samplesheet di esempio fornito nel template.
Sotto core-hello/conf, troviamo due profili test del template: test.config e test_full.config, che sono pensati per testare un piccolo campione di dati e uno di dimensioni complete.
Dato lo scopo della nostra pipeline, non c'è davvero un punto nell'impostare un profilo test di dimensioni complete, quindi sentitevi liberi di ignorare o eliminare test_full.config.
Ci concentreremo sulla configurazione di test.config per essere eseguito sul nostro file greetings.csv con alcuni parametri predefiniti.
5.3.1. Copiare il file greetings.csv¶
Prima dobbiamo copiare il file greetings.csv in un posto appropriato nel nostro progetto pipeline.
Tipicamente i piccoli file di test sono memorizzati nella directory assets, quindi copiamo il file dalla nostra directory di lavoro.
Ora il file greetings.csv è pronto per essere utilizzato come input di test.
5.3.2. Aggiornare il file test.config¶
Ora possiamo aggiornare il file test.config come segue:
| core-hello/conf/test.config | |
|---|---|
Punti chiave:
- Utilizzo di
${projectDir}: Questa è una variabile implicita di Nextflow che punta alla directory dove si trova lo script del flusso di lavoro principale (la radice della pipeline). Utilizzarla garantisce che il percorso funzioni indipendentemente da dove viene eseguita la pipeline. - Percorsi assoluti: Utilizzando
${projectDir}, creiamo un percorso assoluto, che è importante per i dati di test che vengono forniti con la pipeline. - Posizione dei dati di test: Le pipeline nf-core tipicamente memorizzano i dati di test nella directory
assets/all'interno del repository della pipeline per i piccoli file di test, o fanno riferimento a dataset di test esterni per i file più grandi.
E mentre ci siamo, stringiamo i limiti di risorse predefiniti per assicurarci che questo venga eseguito su macchine molto basilari (come le VM minimali in Github Codespaces):
Questo completa le modifiche del codice che dobbiamo fare.
5.4. Eseguire la pipeline con il profilo test¶
È stato molto, ma possiamo finalmente provare a eseguire la pipeline!
Notate che dobbiamo aggiungere --validate_params false alla riga di comando perché non abbiamo ancora configurato la validazione (che arriverà più tardi).
Se avete effettuato tutte le modifiche correttamente, dovrebbe essere eseguita fino al completamento.
Output del comando
N E X T F L O W ~ version 25.10.4
Launching `core-hello/main.nf` [condescending_allen] DSL2 - revision: b9e9b3b8de
Input/output options
input : /workspaces/training/hello-nf-core/core-hello/assets/greetings.csv
outdir : core-hello-results
Institutional config options
config_profile_name : Test profile
config_profile_description: Minimal test dataset to check pipeline function
Generic options
validate_params : false
trace_report_suffix : 2025-11-21_07-29-37
Core Nextflow options
runName : condescending_allen
containerEngine : docker
launchDir : /workspaces/training/hello-nf-core
workDir : /workspaces/training/hello-nf-core/work
projectDir : /workspaces/training/hello-nf-core/core-hello
userName : root
profile : test,docker
configFiles : /workspaces/training/hello-nf-core/core-hello/nextflow.config
!! Only displaying parameters that differ from the pipeline defaults !!
------------------------------------------------------
executor > local (1)
[ed/727b7e] CORE_HELLO:HELLO:sayHello (3) [100%] 3 of 3 ✔
[45/bb6096] CORE_HELLO:HELLO:convertToUpper (3) [100%] 3 of 3 ✔
[81/7e2e34] CORE_HELLO:HELLO:collectGreetings [100%] 1 of 1 ✔
[96/9442a1] CORE_HELLO:HELLO:cowpy [100%] 1 of 1 ✔
-[core/hello] Pipeline completed successfully-
Come potete vedere, questo ha prodotto il tipico riepilogo nf-core all'inizio grazie al subworkflow di inizializzazione, e le righe per ogni modulo ora mostrano i nomi completi PIPELINE:WORKFLOW:module.
5.5. Trovare gli output della pipeline¶
La domanda ora è: dove sono gli output della pipeline? E la risposta è abbastanza interessante: ci sono ora due posti diversi dove cercare i risultati.
Come potreste ricordare da prima, la nostra prima esecuzione del flusso di lavoro appena creato ha prodotto una directory chiamata core-hello-results/ che conteneva vari report di esecuzione e metadati.
Contenuto della directory
core-hello-results
└── pipeline_info
├── execution_report_2025-11-21_04-47-18.html
├── execution_report_2025-11-21_07-29-37.html
├── execution_timeline_2025-11-21_04-47-18.html
├── execution_timeline_2025-11-21_07-29-37.html
├── execution_trace_2025-11-21_04-47-18.txt
├── execution_trace_2025-11-21_07-29-37.txt
├── hello_software_versions.yml
├── params_2025-11-21_04-47-13.json
├── params_2025-11-21_07-29-41.json
├── pipeline_dag_2025-11-21_04-47-18.html
└── pipeline_dag_2025-11-21_07-29-37.html
1 directory, 12 files
Vedete che abbiamo ottenuto un altro set di report di esecuzione oltre a quelli che abbiamo ottenuto dalla prima esecuzione, quando il flusso di lavoro era ancora solo un placeholder. Questa volta vedete tutte le attività che sono state eseguite come previsto.
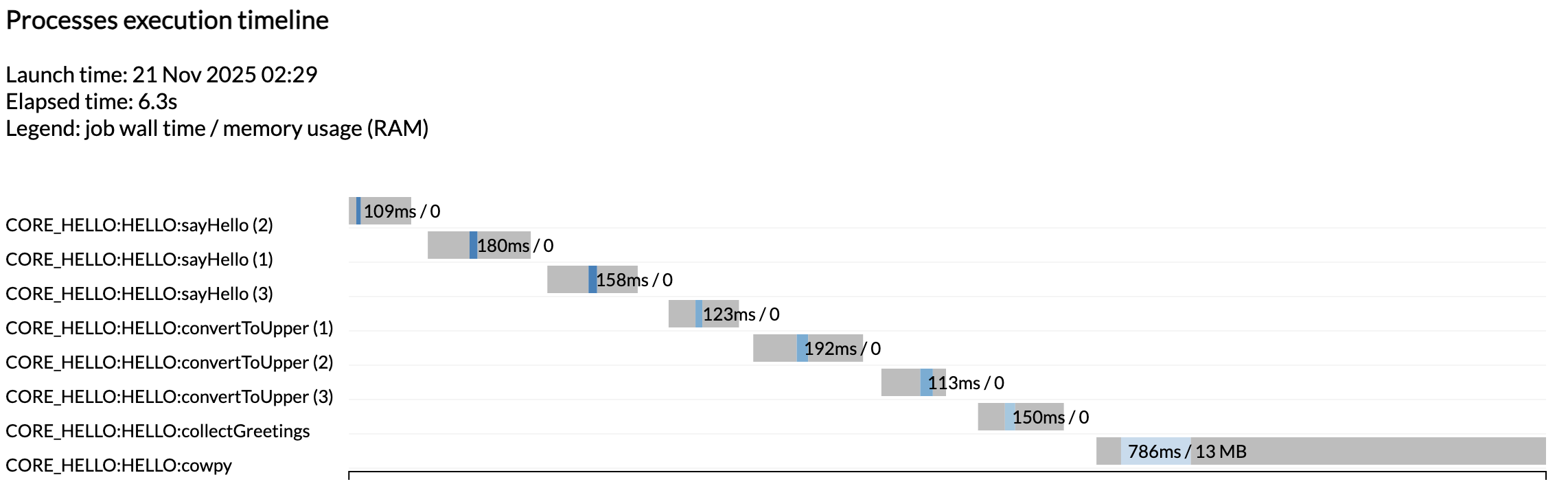
Nota
Ancora una volta le attività non sono state eseguite in parallelo perché stiamo eseguendo su una macchina minimalista in Github Codespaces. Per vederle eseguire in parallelo, provate ad aumentare l'allocazione della CPU del vostro codespace e i limiti di risorse nella configurazione di test.
È fantastico, ma i nostri risultati effettivi della pipeline non sono lì!
Ecco cosa è successo: non abbiamo cambiato nulla ai moduli stessi, quindi gli output gestiti dalle direttive publishDir a livello di modulo vanno ancora in una directory results come specificato nella pipeline originale.
Contenuto della directory
results
├── Bonjour-output.txt
├── COLLECTED-test-batch-output.txt
├── COLLECTED-test-output.txt
├── cowpy-COLLECTED-test-batch-output.txt
├── cowpy-COLLECTED-test-output.txt
├── Hello-output.txt
├── Hola-output.txt
├── UPPER-Bonjour-output.txt
├── UPPER-Hello-output.txt
└── UPPER-Hola-output.txt
0 directories, 10 files
Ah, eccoli, mescolati con gli output delle esecuzioni precedenti della pipeline Hello originale.
Se vogliamo che siano organizzati ordinatamente come gli output della pipeline demo, dovremo cambiare il modo in cui impostiamo la pubblicazione degli output. Vi mostreremo come farlo più tardi in questo corso di formazione.
Ed eccolo! Può sembrare molto lavoro per ottenere lo stesso risultato della pipeline originale, ma ottenete tutti quei bei report generati automaticamente, e ora avete una solida base per sfruttare le funzionalità aggiuntive di nf-core, inclusa la validazione degli input e alcune interessanti capacità di gestione dei metadati che tratteremo in una sezione successiva.
Takeaway¶
Sapete come convertire una pipeline Nextflow normale in una pipeline in stile nf-core utilizzando il template nf-core. Come parte di ciò, avete imparato come rendere un flusso di lavoro componibile e come identificare gli elementi del template nf-core che più comunemente necessitano di essere adattati quando si sviluppa una pipeline personalizzata in stile nf-core.
Cosa c'è dopo?¶
Prendetevi una pausa, è stato un lavoro duro! Quando siete pronti, passate a Part 3: Use an nf-core module per imparare come sfruttare i moduli mantenuti dalla comunità dal repository nf-core/modules.