Część 2: Przepisanie Hello dla nf-core¶
Tłumaczenie wspomagane przez AI - dowiedz się więcej i zasugeruj ulepszenia
W tej drugiej części kursu szkoleniowego Hello nf-core pokażemy Ci, jak utworzyć wersję pipeline'u kompatybilną z nf-core, opartą na projekcie z kursu dla początkujących Hello Nextflow.
Zrobimy to w dwóch fazach: najpierw użyjemy narzędzi nf-core do stworzenia szkieletu pipeline'u, a następnie przeszczepimy na niego istniejący kod 'zwykłego' pipeline'u.
Jeśli nie znasz pipeline'u Hello lub potrzebujesz przypomnienia, zobacz tę stronę informacyjną.
Wskazówka
Ta część kursu wprowadza dwa ważne mechanizmy Nextflow'a, które nie są omówione w kursie wprowadzającym Hello Nextflow: meta maps oraz workflows of workflows — oba szczegółowo opisane w powiązanych Side Quests.
Poniższe instrukcje zawierają niezbędne informacje potrzebne do zrozumienia, jak są one używane w kontekście nf-core, ale może to być dużo do przyswojenia naraz. Jeśli masz czas, zalecamy najpierw przejście przez oba Side Quests (w dowolnej kolejności):
Uwaga
Upewnij się, że znajdujesz się w katalogu hello-nf-core w Swoim terminalu.
1. Zbadanie struktury kodu pipeline'u¶
Projekt nf-core narzuca ścisłe wytyczne dotyczące struktury pipeline'ów oraz organizacji, konfiguracji i dokumentacji kodu.
Zanim przystąpimy do tworzenia pipeline'u, musimy zrozumieć tę strukturę i organizację.
Przyjrzyjmy się więc, jak kod pipeline'u jest zorganizowany w repozytorium nf-core/demo, używając dowiązania symbolicznego pipelines utworzonego w Części 1.
Dla przypomnienia: możesz użyć polecenia tree lub eksploratora plików, aby znaleźć i otworzyć katalog nf-core/demo.
Zawartość katalogu
pipelines/nf-core/demo
├── assets
├── CHANGELOG.md
├── CITATIONS.md
├── CODE_OF_CONDUCT.md
├── conf
├── docs
├── LICENSE
├── main.nf
├── modules
├── modules.json
├── nextflow.config
├── nextflow_schema.json
├── nf-test.config
├── README.md
├── ro-crate-metadata.json
├── subworkflows
├── tests
├── tower.yml
└── workflows
Na razie skupimy się konkretnie na komponentach kodu pipeline'u (main.nf, workflows, subworkflows, modules) i ich wzajemnych relacjach.
1.1. Modularna struktura workflow'ów nf-core¶
Standardowa organizacja kodu pipeline'u nf-core opiera się na strukturze modularnej zaprojektowanej w celu maksymalizacji ponownego użycia kodu, zgodnie z tym, co zostało wprowadzone w Hello Modules, Części 4 kursu Hello Nextflow — choć w prawdziwym stylu nf-core jest to zaimplementowane z nieco większą złożonością. W szczególności pipeline'y nf-core intensywnie korzystają z subworkflow'ów, czyli skryptów workflow'u importowanych przez workflow nadrzędny.
Może to brzmieć nieco abstrakcyjnie, więc przyjrzyjmy się, jak jest to stosowane w praktyce w pipeline'ie nf-core/demo.
Jeśli zajrzysz do pliku main.nf, zobaczysz, że importuje on workflow o nazwie DEMO z workflows/demo.nf, a także kilka modułów i subworkflow'ów.
Oto jak wyglądają relacje między odpowiednimi komponentami kodu:
Nienazwany workflow w main.nf nazywany jest skryptem punktu wejścia. Pełni rolę otoczki dla dwóch rodzajów zagnieżdżonych workflow'ów: workflow'u DEMO zawierającego właściwą logikę analizy, znajdującego się w workflows/demo.nf, oraz zestawu workflow'ów porządkowych zlokalizowanych w subworkflows/.
Workflow demo.nf wywołuje moduły znajdujące się w modules/; zawierają one procesy, które wykonują właściwe kroki analizy.
Uwaga
Subworkflow'y nie są ograniczone do funkcji porządkowych i mogą korzystać z modułów procesów.
Pipeline nf-core/demo pokazany tutaj jest stosunkowo prosty, ale inne pipeline'y nf-core (takie jak nf-core/rnaseq) wykorzystują subworkflow'y biorące udział w samej analizie.
Przyjrzyjmy się teraz szczegółowo tym komponentom.
1.2. Skrypt punktu wejścia: main.nf¶
Skrypt main.nf jest punktem wejścia, od którego Nextflow zaczyna działanie po wykonaniu nextflow run nf-core/demo.
Oznacza to, że gdy uruchamiasz nextflow run nf-core/demo, Nextflow automatycznie odnajduje i wykonuje skrypt main.nf.
Działa to dla każdego pipeline'u Nextflow'a stosującego tę konwencjonalną nazwę i strukturę, nie tylko dla pipeline'ów nf-core.
Użycie skryptu punktu wejścia ułatwia uruchamianie standardowych subworkflow'ów 'porządkowych' przed i po wykonaniu właściwego skryptu analizy. Omówimy je po przeglądzie workflow'u analizy i jego modułów.
1.3. Skrypt analizy: workflows/demo.nf¶
Workflow workflows/demo.nf zawiera centralną logikę pipeline'u.
Jest zbudowany podobnie do zwykłego workflow'u Nextflow'a, z tą różnicą, że jest zaprojektowany do wywoływania z workflow'u nadrzędnego, co wymaga kilku dodatkowych funkcji.
Omówimy istotne różnice w następnej części tego kursu, gdy zajmiemy się konwersją prostego pipeline'u Hello z Hello Nextflow do postaci kompatybilnej z nf-core.
Workflow demo.nf wywołuje moduły znajdujące się w modules/, które omówimy poniżej.
Uwaga
Niektóre workflow'y analizy nf-core wykazują dodatkowe poziomy zagnieżdżenia poprzez wywoływanie subworkflow'ów niższego poziomu. Służy to głównie do łączenia dwóch lub więcej modułów, które są często używane razem, w łatwo wielokrotnego użytku segmenty pipeline'u. Przykłady możesz zobaczyć, przeglądając dostępne subworkflow'y nf-core na stronie nf-core.
Gdy skrypt analizy korzysta z subworkflow'ów, są one przechowywane w katalogu subworkflows/.
1.4. Moduły¶
Moduły zawierają kod procesów, zgodnie z opisem w Części 4 kursu szkoleniowego Hello Nextflow.
W projekcie nf-core moduły są zorganizowane w wielopoziomowej strukturze zagnieżdżonej, odzwierciedlającej zarówno ich pochodzenie, jak i zawartość.
Na najwyższym poziomie moduły są podzielone na nf-core i local (niebędące częścią projektu nf-core), a następnie umieszczane w katalogu nazwanym od narzędzia lub narzędzi, które opakowują.
Jeśli narzędzie należy do zestawu narzędzi (pakietu zawierającego wiele narzędzi), istnieje pośredni poziom katalogu nazwany od tego zestawu.
Możesz zobaczyć to zastosowane w praktyce w modułach pipeline'u nf-core/demo:
Zawartość katalogu
Widać tutaj, że moduły fastqc i multiqc znajdują się na najwyższym poziomie w modułach nf-core, natomiast moduł trim jest umieszczony pod zestawem narzędzi, do którego należy — seqtk.
W tym przypadku nie ma modułów local.
Plik kodu modułu opisujący proces zawsze nosi nazwę main.nf i towarzyszy mu zestaw testów oraz pliki .yml, które na razie pominiemy.
Łącznie skrypt punktu wejścia, workflow analizy i moduły są wystarczające do uruchomienia 'interesujących' części pipeline'u. Wiemy jednak, że są tam również subworkflow'y porządkowe, więc przyjrzyjmy się im teraz.
1.5. Subworkflow'y porządkowe¶
Podobnie jak moduły, subworkflow'y są podzielone na katalogi local i nf-core, a każdy subworkflow ma własną zagnieżdżoną strukturę katalogów z własnym skryptem main.nf, testami i plikiem .yml.
Zawartość katalogu
pipelines/nf-core/demo/subworkflows
├── local
│ └── utils_nfcore_demo_pipeline
│ └── main.nf
└── nf-core
├── utils_nextflow_pipeline
│ ├── main.nf
│ ├── meta.yml
│ └── tests
├── utils_nfcore_pipeline
│ ├── main.nf
│ ├── meta.yml
│ └── tests
└── utils_nfschema_plugin
├── main.nf
├── meta.yml
└── tests
9 directories, 7 files
Jak wspomniano powyżej, pipeline nf-core/demo nie zawiera żadnych subworkflow'ów specyficznych dla analizy, więc wszystkie widoczne tutaj subworkflow'y są tzw. workflow'ami 'porządkowymi' lub 'narzędziowymi', co sygnalizuje przedrostek utils_ w ich nazwach.
To właśnie te subworkflow'y generują efektowny nagłówek nf-core w wyjściu konsoli, wśród innych funkcji pomocniczych.
Wskazówka
Poza wzorcem nazewniczym, kolejną wskazówką, że te subworkflow'y nie wykonują żadnych funkcji związanych z analizą, jest to, że nie wywołują żadnych procesów.
To kończy przegląd podstawowych komponentów kodu składających się na pipeline nf-core/demo.
Podsumowanie¶
Masz teraz ogólne pojęcie o modularnej strukturze pipeline'ów nf-core.
Co dalej?¶
Utwórz szkielet pipeline'u używając narzędzi nf-core.
2. Stworzenie nowego projektu pipeline'u¶
Jak widziałeś, pipeline'y nf-core mają ustandaryzowaną strukturę z wieloma plikami pomocniczymi. Tworzenie tego wszystkiego od zera byłoby bardzo żmudne, dlatego społeczność nf-core opracowała narzędzia, które zamiast tego korzystają z szablonu, aby przyspieszyć ten proces.
2.1. Uruchomienie narzędzia do tworzenia pipeline'u opartego na szablonie¶
Zacznijmy od stworzenia nowego pipeline'u za pomocą polecenia nf-core pipelines create.
Spowoduje to utworzenie nowego szkieletu pipeline'u przy użyciu podstawowego szablonu nf-core, dostosowanego za pomocą nazwy pipeline'u, opisu i autora.
Uruchomienie tego polecenia otworzy tekstowy interfejs użytkownika (TUI) do tworzenia pipeline'u:
Ten TUI poprosi Cię o podanie podstawowych informacji o pipeline'ie i pozwoli wybrać funkcje do włączenia lub wyłączenia w szkielecie pipeline'u.
- Na ekranie powitalnym kliknij Let's go!.
- Na ekranie
Choose pipeline typekliknij Custom. - Wprowadź szczegóły Swojego pipeline'u w następujący sposób (zastępując
< YOUR NAME >Swoim imieniem), następnie kliknij Next.
[ ] GitHub organisation: core
[ ] Workflow name: hello
[ ] A short description of your pipeline: A basic nf-core style version of Hello Nextflow
[ ] Name of the main author(s): < YOUR NAME >
- Na ekranie Template features ustaw
Toggle all featuresna off, następnie selektywnie włącz następujące opcje. Sprawdź Swoje wybory i kliknij Continue.
[ ] Add testing profiles
[ ] Use nf-core components
[ ] Use nf-schema
[ ] Add configuration files
[ ] Add documentation
- Na ekranie
Final detailskliknij Finish. Poczekaj na utworzenie pipeline'u, następnie kliknij Continue. - Na ekranie Create GitHub repository kliknij Finish without creating a repo. Wyświetlone zostaną instrukcje tworzenia repozytorium GitHub na później. Zignoruj je i kliknij Close.
Po zamknięciu TUI powinieneś zobaczyć następujące wyjście konsoli.
Wyjście polecenia
W wyjściu konsoli nie ma wyraźnego potwierdzenia, że utworzenie pipeline'u się powiodło, ale powinieneś zobaczyć nowy katalog o nazwie core-hello.
Wyświetl zawartość nowego katalogu, aby zobaczyć, ile pracy zaoszczędziłeś używając szablonu.
Zawartość katalogu
core-hello/
├── README.md
├── assets
│ ├── samplesheet.csv
│ └── schema_input.json
├── conf
│ ├── base.config
│ ├── modules.config
│ ├── test.config
│ └── test_full.config
├── docs
│ ├── README.md
│ ├── output.md
│ └── usage.md
├── main.nf
├── modules.json
├── nextflow.config
├── nextflow_schema.json
├── subworkflows
│ ├── local
│ │ └── utils_nfcore_hello_pipeline
│ │ └── main.nf
│ └── nf-core
│ ├── utils_nextflow_pipeline
│ │ ├── main.nf
│ │ ├── meta.yml
│ │ └── tests
│ │ ├── main.function.nf.test
│ │ ├── main.function.nf.test.snap
│ │ ├── main.workflow.nf.test
│ │ └── nextflow.config
│ ├── utils_nfcore_pipeline
│ │ ├── main.nf
│ │ ├── meta.yml
│ │ └── tests
│ │ ├── main.function.nf.test
│ │ ├── main.function.nf.test.snap
│ │ ├── main.workflow.nf.test
│ │ ├── main.workflow.nf.test.snap
│ │ └── nextflow.config
│ └── utils_nfschema_plugin
│ ├── main.nf
│ ├── meta.yml
│ └── tests
│ ├── main.nf.test
│ ├── nextflow.config
│ └── nextflow_schema.json
└── workflows
└── hello.nf
15 directories, 34 files
To dużo plików! Nie martw się, jeśli czujesz się trochę zagubiony; omówimy ważne części wkrótce, a następnie krok po kroku przez resztę kursu.
Ogólnie rzecz biorąc, powinno to wyglądać podobnie do struktury kodu, którą zaobserwowaliśmy dla pipeline'u nf-core/demo, z tą różnicą, że nie ma tutaj katalogu modules.
2.2. Sprawdzenie, czy szkielet jest funkcjonalny¶
Wierz lub nie, mimo że nie dodałeś jeszcze żadnych modułów do wykonywania rzeczywistej pracy, szkielet pipeline'u można uruchomić używając profilu testowego, tak samo jak uruchamialiśmy pipeline nf-core/demo.
Wyjście polecenia
N E X T F L O W ~ version 25.10.4
Launching `./core-hello/main.nf` [scruffy_marconi] DSL2 - revision: b9e9b3b8de
Downloading plugin nf-schema@2.5.1
Input/output options
input : https://raw.githubusercontent.com/nf-core/test-datasets/viralrecon/samplesheet/samplesheet_test_illumina_amplicon.csv
outdir : core-hello-results
Institutional config options
config_profile_name : Test profile
config_profile_description: Minimal test dataset to check pipeline function
Generic options
trace_report_suffix : 2025-11-21_04-47-18
Core Nextflow options
runName : scruffy_marconi
containerEngine : docker
launchDir : /workspaces/training/hello-nf-core
workDir : /workspaces/training/hello-nf-core/work
projectDir : /workspaces/training/hello-nf-core/core-hello
userName : root
profile : docker,test
configFiles : /workspaces/training/hello-nf-core/core-hello/nextflow.config
!! Only displaying parameters that differ from the pipeline defaults !!
------------------------------------------------------
-[core/hello] Pipeline completed successfully-
To pokazuje, że całe podstawowe okablowanie jest na miejscu. Gdzie więc są wyniki? Czy w ogóle jakieś są?
W rzeczywistości został utworzony nowy katalog wyników o nazwie core-hello-results zawierający standardowe raporty wykonania:
Zawartość katalogu
core-hello-results
└── pipeline_info
├── execution_report_2025-11-21_04-47-18.html
├── execution_timeline_2025-11-21_04-47-18.html
├── execution_trace_2025-11-21_04-47-18.txt
├── hello_software_versions.yml
├── params_2025-11-21_04-47-18.json
└── pipeline_dag_2025-11-21_04-47-18.html
1 directory, 6 files
Możesz zajrzeć do raportów, aby zobaczyć, co zostało uruchomione, a odpowiedzią jest: nic w ogóle!

Przyjrzyjmy się bliżej temu, co faktycznie znajduje się w środku.
2.3. Zbadanie struktury szkieletu¶
Jeśli pamiętasz strukturę pipeline'u nf-core/demo, był tam plik main.nf zawierający workflow punktu wejścia opakowujący workflow DEMO.
Teraz, jeśli otworzysz plik main.nf w nowo utworzonym projekcie, zobaczysz, że importuje on workflow o nazwie HELLO z workflows/hello.nf.
Jest to bezpośredni odpowiednik workflow'u DEMO, choć na razie jest to tylko zastępnik.
Oto jak wygląda ogólna struktura szkieletu pipeline'u:
Powinno to przypominać strukturę pipeline'u nf-core/demo!
Jedyna prawdziwa różnica polega na tym, że workflow DEMO zawierał procesy z modułów. Tutaj równoważny workflow HELLO nie zawiera jeszcze żadnych procesów.
Przyjrzyjmy się bliżej.
2.4. Zbadanie zastępczego workflow'u¶
Pełni on rolę zastępnika dla naszego workflow'u analizy, z niektórymi funkcjami nf-core już na miejscu.
W porównaniu do podstawowego workflow'u Nextflow'a, takiego jak ten opracowany w Hello Nextflow, zauważysz kilka nowych rzeczy (podświetlone linie powyżej):
- Blok workflow ma nazwę
- Wejścia workflow'u są deklarowane za pomocą słowa kluczowego
take:, a konstrukcja kanału jest przenoszona do workflow'u nadrzędnego - Zawartość workflow'u jest umieszczona w bloku
main: - Wyjścia są deklarowane za pomocą słowa kluczowego
emit:
Są to opcjonalne funkcje Nextflow'a, które sprawiają, że workflow jest kompozycyjny, co oznacza, że może być wywoływany z innego workflow'u.
Blok Channel.topic
Być może zauważyłeś blok def topic_versions = Channel.topic("versions") zaczynający się od linii 17.
Jest to standardowy kod porządkowy, który automatycznie zbiera informacje o wersjach oprogramowania ze wszystkich modułów.
nf-core wdraża ten mechanizm we wszystkich pipeline'ach w 2026 roku, więc znajdziesz go we wszystkich nowych pipeline'ach.
Część 4 tego kursu szczegółowo wyjaśnia, jak działa.
Będziemy musieli podłączyć odpowiednią logikę z naszego workflow'u do tej struktury.
Podsumowanie¶
Wiesz już, jak stworzyć szkielet pipeline'u używając narzędzi nf-core i porównać go ze strukturą pipeline'u demo.
Co dalej?¶
Naucz się, jak uczynić prosty workflow kompozycyjnym jako wstęp do uczynienia go kompatybilnym z nf-core.
3. Uczynienie workflow'u Hello Nextflow kompozycyjnym¶
Teraz czas rozpocząć pracę nad integracją naszego workflow'u do szkieletu nf-core.
Przypominamy, że pracujemy z workflow'em przedstawionym w kursie szkoleniowym Hello Nextflow. Został on napisany jako prosty nienazwany workflow, który może być uruchomiony samodzielnie.
Aby jasno określić, które części oryginalnego workflow'u powinny trafić w które miejsce szkieletu nf-core, zaczniemy od przekształcenia oryginalnego workflow'u Hello w kompozycyjny workflow, który może być uruchamiany z poziomu workflow'u nadrzędnego, jak wymaga szablon nf-core.
Oto co chcemy teraz zbudować:
W praktyce chcemy odwzorować modularną strukturę szkieletu nf-core, ale na razie z mniejszą złożonością.
Dostarczamy Ci czystą, w pełni funkcjonalną kopię ukończonego workflow'u Hello Nextflow w katalogu original-hello wraz z jego modułami i domyślnym plikiem CSV, którego oczekuje jako wejścia.
Zawartość katalogu
Możesz go uruchomić, aby upewnić się, że działa:
Wyjście polecenia
Jeśli to działa, możesz zacząć wprowadzać zmiany.
3.1. Modyfikacja oryginalnego workflow'u Hello¶
Otwórzmy plik workflow'u hello.nf, aby sprawdzić kod, który jest pokazany w całości poniżej (nie licząc procesów, które są w modułach):
Jak widać, ten workflow został napisany jako prosty nienazwany workflow, który może być uruchomiony samodzielnie. Aby uczynić go kompozycyjnym, wprowadzamy następujące zmiany:
- Nadanie workflow'owi nazwy
- Zastąpienie konstrukcji kanału instrukcją
take: - Poprzedzenie operacji workflow'u instrukcją
main: - Dodanie instrukcji
emit:
Przejdźmy przez niezbędne zmiany jedna po drugiej.
3.1.1. Nazwanie workflow'u¶
Najpierw nadajmy workflow'owi nazwę, abyśmy mogli się do niego odwoływać z workflow'u nadrzędnego.
Te same konwencje dotyczą nazw workflow'ów, co nazw modułów.
3.1.2. Zastąpienie konstrukcji kanału instrukcją take¶
Teraz zastąp konstrukcję kanału prostą instrukcją take deklarującą oczekiwane wejścia.
To pozostawia szczegóły sposobu dostarczania wejść workflow'owi nadrzędnemu.
Skoro już przy tym jesteśmy, możemy również zakomentować linię params.greeting = 'greetings.csv':
Uwaga
Jeśli masz zainstalowane rozszerzenie serwera języka Nextflow, sprawdzanie składni podświetli Twój kod czerwonymi falkami.
Dzieje się tak, ponieważ jeśli umieścisz instrukcję take:, musisz również mieć main:.
Dodamy to w następnym kroku.
3.1.3. Poprzedzenie operacji workflow'u instrukcją main¶
Następnie dodaj instrukcję main przed pozostałymi operacjami wywoływanymi w ciele workflow'u.
To w zasadzie mówi: 'to jest to, co ten workflow robi'.
3.1.4. Dodanie instrukcji emit¶
Na koniec dodaj instrukcję emit deklarującą końcowe wyjścia workflow'u.
To jest nowy dodatek do kodu w porównaniu z oryginalnym workflow'em.
3.1.5. Podsumowanie ukończonych zmian¶
Jeśli wykonałeś wszystkie zmiany zgodnie z opisem, Twój workflow powinien teraz wyglądać następująco:
To opisuje wszystko, czego Nextflow potrzebuje, Z WYJĄTKIEM tego, co podać do kanału wejściowego. Zostanie to zdefiniowane w workflow'ie nadrzędnym, nazywanym również workflow'em punktu wejścia.
3.2. Stworzenie fikcyjnego workflow'u punktu wejścia¶
Zanim zintegrujemy nasz kompozycyjny workflow do złożonego szkieletu nf-core, sprawdźmy, czy działa poprawnie. Możemy stworzyć prosty fikcyjny workflow punktu wejścia, aby przetestować kompozycyjny workflow w izolacji.
Utwórz pusty plik o nazwie main.nf w tym samym katalogu original-hello.
Skopiuj następujący kod do pliku main.nf.
Są tutaj dwie ważne obserwacje:
- Sposób wywoływania zaimportowanego workflow'u jest zasadniczo taki sam jak w przypadku modułów.
- Wszystko, co jest związane z wprowadzaniem wejść (parametr wejściowy i konstrukcja kanału) jest teraz zadeklarowane w nadrzędnym skrypcie.
Uwaga
Nazwanie pliku workflow'u punktu wejścia main.nf jest konwencją, a nie wymogiem.
Jeśli zastosujesz się do tej konwencji, możesz pominąć podanie nazwy pliku workflow'u w poleceniu nextflow run.
Nextflow automatycznie poszuka pliku o nazwie main.nf w katalogu wykonania.
Możesz jednak nazwać plik workflow'u punktu wejścia inaczej, jeśli wolisz.
W takim przypadku pamiętaj, aby określić nazwę pliku workflow'u w poleceniu nextflow run.
3.3. Sprawdzenie, czy workflow działa¶
W końcu mamy wszystkie elementy potrzebne do zweryfikowania, że kompozycyjny workflow działa. Uruchommy go!
Tutaj widać zalety używania konwencji nazewniczej main.nf.
Gdybyśmy nazwali workflow punktu wejścia something_else.nf, musielibyśmy wykonać nextflow run original-hello/something_else.nf.
Jeśli wykonałeś wszystkie zmiany poprawnie, powinno to uruchomić się do końca.
Wyjście polecenia
N E X T F L O W ~ version 25.10.4
Launching `original-hello/main.nf` [friendly_wright] DSL2 - revision: 1ecd2d9c0a
executor > local (8)
[24/c6c0d8] HELLO:sayHello (3) | 3 of 3 ✔
[dc/721042] HELLO:convertToUpper (3) | 3 of 3 ✔
[48/5ab2df] HELLO:collectGreetings | 1 of 1 ✔
[e3/693b7e] HELLO:cowpy | 1 of 1 ✔
Output: /workspaces/training/hello-nf-core/work/e3/693b7e48dc119d0c54543e0634c2e7/cowpy-COLLECTED-test-batch-output.txt
To oznacza, że pomyślnie zaktualizowaliśmy nasz workflow HELLO, aby był kompozycyjny.
Podsumowanie¶
Wiesz, jak uczynić workflow kompozycyjnym, nadając mu nazwę oraz dodając instrukcje take, main i emit, a także jak wywoływać go z workflow'u punktu wejścia.
Co dalej?¶
Naucz się, jak przeszczepić podstawowy kompozycyjny workflow na szkielet nf-core.
4. Dopasowanie zaktualizowanej logiki workflow'u do zastępczego workflow'u¶
Teraz, gdy zweryfikowaliśmy poprawność naszego kompozycyjnego workflow'u, wróćmy do szkieletu nf-core, który utworzyliśmy w sekcji 1. Chcemy zintegrować opracowany właśnie kod ze strukturą szablonu, więc wynik końcowy powinien wyglądać mniej więcej tak.
Jak więc to osiągnąć? Spójrzmy na obecną zawartość workflow'u HELLO w core-hello/workflows/hello.nf (szkielet nf-core).
Podświetlone linie definiują strukturę kompozycyjnego workflow'u: workflow HELLO {, take:, main: i emit:.
Duży blok między liniami 17–34 jest bardziej rozbudowany: obsługuje przechwytywanie wersji oprogramowania przy użyciu topic channels — mechanizmu, który nf-core wdraża we wszystkich pipeline'ach w 2026 roku.
Wyjaśnimy go w Części 4; na razie traktuj go jako standardowy kod, który możesz pozostawić bez zmian.
Musimy dodać odpowiednią logikę z kompozycyjnej wersji oryginalnego workflow'u, który opracowaliśmy w sekcji 2.
Zamierzamy zająć się tym w następujących etapach:
- Skopiowanie modułów i ustawienie importów modułów
- Pozostawienie deklaracji
takebez zmian - Dodanie logiki workflow'u do bloku
main - Aktualizacja bloku
emit
Uwaga
Na razie zignorujemy blok przechwytywania wersji. Część 4 wyjaśnia, jak działa.
4.1. Skopiowanie modułów i ustawienie importów modułów¶
Cztery procesy z naszego workflow'u Hello Nextflow są przechowywane jako moduły w original-hello/modules/.
Musimy skopiować te moduły do struktury projektu nf-core (pod core-hello/modules/local/) i dodać instrukcje importu do pliku workflow'u nf-core.
Najpierw skopiujmy pliki modułów z original-hello/ do core-hello/:
Powinieneś teraz zobaczyć katalog modułów wymieniony pod core-hello/.
Zawartość katalogu
Teraz skonfigurujmy instrukcje importu modułów.
To były instrukcje importu w workflow'ie original-hello/hello.nf:
| original-hello/hello.nf | |
|---|---|
Otwórz plik core-hello/workflows/hello.nf i przenieś te instrukcje importu do niego, jak pokazano poniżej.
Jeszcze dwie interesujące obserwacje:
- Zaadaptowaliśmy formatowanie instrukcji importu, aby były zgodne z konwencją stylu nf-core.
- Zaktualizowaliśmy ścieżki względne do modułów, aby odzwierciedlały fakt, że są teraz przechowywane na innym poziomie zagnieżdżenia.
4.2. Pozostawienie deklaracji take bez zmian¶
Projekt nf-core ma wiele wbudowanych funkcji związanych z koncepcją samplesheet, który jest zazwyczaj plikiem CSV zawierającym dane kolumnowe.
Ponieważ to jest zasadniczo tym, czym jest nasz plik greetings.csv, zachowamy obecną deklarację take bez zmian i po prostu zaktualizujemy nazwę kanału wejściowego w następnym kroku.
Obsługa wejścia będzie wykonywana przed tym workflow'iem (nie w tym pliku kodu).
4.3. Dodanie logiki workflow'u do bloku main¶
Teraz, gdy nasze moduły są dostępne dla workflow'u, możemy podłączyć logikę workflow'u do bloku main.
Przypominamy, że to jest odpowiedni kod w oryginalnym workflow'ie, który nie zmienił się zbytnio, gdy uczyniliśmy go kompozycyjnym (dodaliśmy tylko linię main:):
Musimy skopiować kod, który następuje po main: do nowej wersji workflow'u.
Jest tam już fragment związany z przechwytywaniem wersji uruchamianych narzędzi. Na razie zostawimy to w spokoju (zajmiemy się tym później).
Zachowamy inicjalizację ch_versions = channel.empty() na górze, następnie wstawimy naszą logikę, zachowując zestawianie wersji na końcu.
Ta kolejność ma sens, ponieważ w prawdziwym projekcie procesy emitowałyby informacje o wersjach, które byłyby dodawane do kanału ch_versions podczas uruchamiania.
Zauważysz, że dodaliśmy również pustą linię przed main:, aby kod był bardziej czytelny.
To wygląda świetnie, ale nadal musimy zaktualizować nazwę kanału, który przekazujemy do procesu sayHello() z greeting_ch na ch_samplesheet, jak pokazano poniżej, aby pasowała do tego, co jest napisane pod słowem kluczowym take:.
Teraz logika workflow'u jest poprawnie podłączona.
4.4. Aktualizacja bloku emit¶
Na koniec musimy zaktualizować blok emit, aby uwzględnić deklarację końcowych wyników workflow'u.
To kończy modyfikacje, które musimy wprowadzić do samego workflow'u HELLO. W tym momencie osiągnęliśmy ogólną strukturę kodu, którą zamierzaliśmy wdrożyć.
Podsumowanie¶
Wiesz, jak dopasować podstawowe elementy kompozycyjnego workflow'u do zastępczego workflow'u nf-core.
Co dalej?¶
Naucz się, jak dostosować sposób obsługi wejść w szkielecie pipeline'u nf-core.
5. Dostosowanie obsługi wejść¶
Teraz, gdy pomyślnie zintegrowaliśmy logikę workflow'u do szkieletu nf-core, musimy zająć się jeszcze jednym krytycznym elementem: zapewnieniem, że nasze dane wejściowe są prawidłowo przetwarzane.
Szablon nf-core jest wyposażony w zaawansowaną obsługę wejść zaprojektowaną dla złożonych zestawów danych genomicznych, więc musimy ją dostosować do pracy z naszym prostszym plikiem greetings.csv.
5.1. Identyfikacja miejsca obsługi wejść¶
Pierwszym krokiem jest ustalenie, gdzie odbywa się obsługa wejść.
Możesz sobie przypomnieć, że kiedy przepisaliśmy workflow Hello Nextflow, aby był kompozycyjny, przenieśliśmy deklarację parametru wejściowego o jeden poziom wyżej, do workflow'u punktu wejścia main.nf.
Spójrzmy więc na workflow punktu wejścia najwyższego poziomu main.nf, który został utworzony jako część szkieletu pipeline'u:
Projekt nf-core intensywnie wykorzystuje zagnieżdżone subworkflow'y, więc ta część może być na początku trochę myląca.
To, co tutaj ma znaczenie, to fakt, że zdefiniowane są dwa workflow'y:
CORE_HELLOto cienka otoczka do uruchamiania workflow'u HELLO, który właśnie zakończyliśmy adaptować wcore-hello/workflows/hello.nf.- Nienazwany workflow, który wywołuje
CORE_HELLOoraz dwa inne subworkflow'y:PIPELINE_INITIALISATIONiPIPELINE_COMPLETION.
Oto diagram pokazujący, jak się do siebie odnoszą:
Co ważne, nie możemy znaleźć na tym poziomie żadnego kodu konstruującego kanał wejściowy — tylko odniesienia do samplesheet dostarczonego przez parametr --input.
Trochę poszukiwań ujawnia, że obsługa wejść jest wykonywana przez subworkflow PIPELINE_INITIALISATION, co jest całkiem stosowne. Jest on importowany z core-hello/subworkflows/local/utils_nfcore_hello_pipeline/main.nf.
Jeśli otworzymy ten plik i przewiniemy w dół, natrafimy na ten fragment kodu:
To jest fabryka kanałów, która parsuje samplesheet i przekazuje go dalej w formie gotowej do użycia przez workflow HELLO.
Uwaga
Składnia powyżej różni się nieco od tego, czego używaliśmy wcześniej, ale zasadniczo:
jest równoważne temu:
Ten kod obejmuje pewne kroki parsowania i walidacji, które są wysoce specyficzne dla przykładowego samplesheet dołączonego do szablonu pipeline'u nf-core — w chwili pisania jest on bardzo domenowo-specyficzny i nieodpowiedni dla naszego prostego projektu.
5.2. Zastąpienie kodu kanału wejściowego z szablonu¶
Dobrą wiadomością jest to, że potrzeby naszego pipeline'u są znacznie prostsze, więc możemy zastąpić to wszystko kodem konstrukcji kanału, który opracowaliśmy w oryginalnym workflow'ie Hello Nextflow.
Przypominamy, że konstrukcja kanału wyglądała tak (jak widać w katalogu rozwiązań):
| solutions/composable-hello/main.nf | |
|---|---|
Musimy więc po prostu podłączyć to do workflow'u inicjalizacji, z drobnymi zmianami: aktualizujemy nazwę kanału z greeting_ch na ch_samplesheet i nazwę parametru z params.greeting na params.input (zobacz podświetloną linię).
| core-hello/subworkflows/local/utils_nfcore_hello_pipeline/main.nf | |
|---|---|
To kończy zmiany, które musimy wprowadzić, aby przetwarzanie wejść działało.
W obecnej formie nie pozwoli nam to skorzystać z wbudowanych możliwości nf-core do walidacji schematu, ale możemy dodać to później. Na razie skupiamy się na tym, aby było to jak najprostsze, aby uzyskać coś, co możemy pomyślnie uruchomić na danych testowych.
5.3. Aktualizacja profilu testowego¶
Mówiąc o danych testowych i parametrach, zaktualizujmy profil testowy tego pipeline'u, aby używał mini-samplesheet greetings.csv zamiast przykładowego samplesheet dostarczonego w szablonie.
Pod core-hello/conf znajdujemy dwa szablonowe profile testowe: test.config i test_full.config, które są przeznaczone do testowania małej próbki danych i pełnowymiarowej.
Biorąc pod uwagę cel naszego pipeline'u, nie ma sensu konfigurowanie profilu testowego pełnowymiarowego, więc możesz zignorować lub usunąć test_full.config.
Skupimy się na skonfigurowaniu test.config do uruchomienia na naszym pliku greetings.csv z kilkoma domyślnymi parametrami.
5.3.1. Skopiowanie pliku greetings.csv¶
Najpierw musimy skopiować plik greetings.csv do odpowiedniego miejsca w naszym projekcie pipeline'u.
Zazwyczaj małe pliki testowe są przechowywane w katalogu assets, więc skopiujmy plik z naszego katalogu roboczego.
Teraz plik greetings.csv jest gotowy do użycia jako dane wejściowe testowe.
5.3.2. Aktualizacja pliku test.config¶
Teraz możemy zaktualizować plik test.config w następujący sposób:
Kluczowe punkty:
- Używanie
${projectDir}: To jest niejawna zmienna Nextflow'a, która wskazuje na katalog, w którym znajduje się główny skrypt workflow'u (katalog główny pipeline'u). Użycie jej zapewnia, że ścieżka działa niezależnie od tego, skąd pipeline jest uruchamiany. - Ścieżki bezwzględne: Używając
${projectDir}, tworzymy ścieżkę bezwzględną, co jest ważne dla danych testowych dostarczanych z pipeline'em. - Lokalizacja danych testowych: Pipeline'y nf-core zazwyczaj przechowują dane testowe w katalogu
assets/w repozytorium pipeline'u dla małych plików testowych lub odwołują się do zewnętrznych zestawów danych testowych dla większych plików.
Skoro już przy tym jesteśmy, zaostrzmy domyślne limity zasobów, aby upewnić się, że będzie to działać na bardzo podstawowych maszynach (jak minimalne maszyny wirtualne w Github Codespaces):
To kończy modyfikacje kodu, które musimy wykonać.
5.4. Uruchomienie pipeline'u z profilem testowym¶
To było dużo, ale w końcu możemy spróbować uruchomić pipeline!
Zauważ, że musimy dodać --validate_params false do wiersza poleceń, ponieważ nie skonfigurowaliśmy jeszcze walidacji (to przyjdzie później).
Jeśli wykonałeś wszystkie modyfikacje poprawnie, powinno to uruchomić się do końca.
Wyjście polecenia
N E X T F L O W ~ version 25.10.4
Launching `core-hello/main.nf` [condescending_allen] DSL2 - revision: b9e9b3b8de
Input/output options
input : /workspaces/training/hello-nf-core/core-hello/assets/greetings.csv
outdir : core-hello-results
Institutional config options
config_profile_name : Test profile
config_profile_description: Minimal test dataset to check pipeline function
Generic options
validate_params : false
trace_report_suffix : 2025-11-21_07-29-37
Core Nextflow options
runName : condescending_allen
containerEngine : docker
launchDir : /workspaces/training/hello-nf-core
workDir : /workspaces/training/hello-nf-core/work
projectDir : /workspaces/training/hello-nf-core/core-hello
userName : root
profile : test,docker
configFiles : /workspaces/training/hello-nf-core/core-hello/nextflow.config
!! Only displaying parameters that differ from the pipeline defaults !!
------------------------------------------------------
executor > local (1)
[ed/727b7e] CORE_HELLO:HELLO:sayHello (3) [100%] 3 of 3 ✔
[45/bb6096] CORE_HELLO:HELLO:convertToUpper (3) [100%] 3 of 3 ✔
[81/7e2e34] CORE_HELLO:HELLO:collectGreetings [100%] 1 of 1 ✔
[96/9442a1] CORE_HELLO:HELLO:cowpy [100%] 1 of 1 ✔
-[core/hello] Pipeline completed successfully-
Jak widać, wygenerowało to typowe podsumowanie nf-core na początku dzięki subworkflow'owi inicjalizacji, a linie dla każdego modułu teraz pokazują pełne nazwy PIPELINE:WORKFLOW:moduł.
5.5. Znalezienie wyników pipeline'u¶
Pytanie brzmi teraz: gdzie są wyniki pipeline'u? A odpowiedź jest dość interesująca: są teraz dwa różne miejsca, w których należy szukać wyników.
Jak możesz sobie przypomnieć z wcześniejszych sekcji, nasze pierwsze uruchomienie nowo utworzonego workflow'u wytworzyło katalog o nazwie core-hello-results/, który zawierał różne raporty wykonania i metadane.
Zawartość katalogu
core-hello-results
└── pipeline_info
├── execution_report_2025-11-21_04-47-18.html
├── execution_report_2025-11-21_07-29-37.html
├── execution_timeline_2025-11-21_04-47-18.html
├── execution_timeline_2025-11-21_07-29-37.html
├── execution_trace_2025-11-21_04-47-18.txt
├── execution_trace_2025-11-21_07-29-37.txt
├── hello_software_versions.yml
├── params_2025-11-21_04-47-13.json
├── params_2025-11-21_07-29-41.json
├── pipeline_dag_2025-11-21_04-47-18.html
└── pipeline_dag_2025-11-21_07-29-37.html
1 directory, 12 files
Widzisz, że otrzymaliśmy kolejny zestaw raportów wykonania oprócz tych z pierwszego uruchomienia, gdy workflow był jeszcze tylko zastępczy. Tym razem widać wszystkie zadania, które zostały uruchomione zgodnie z oczekiwaniami.
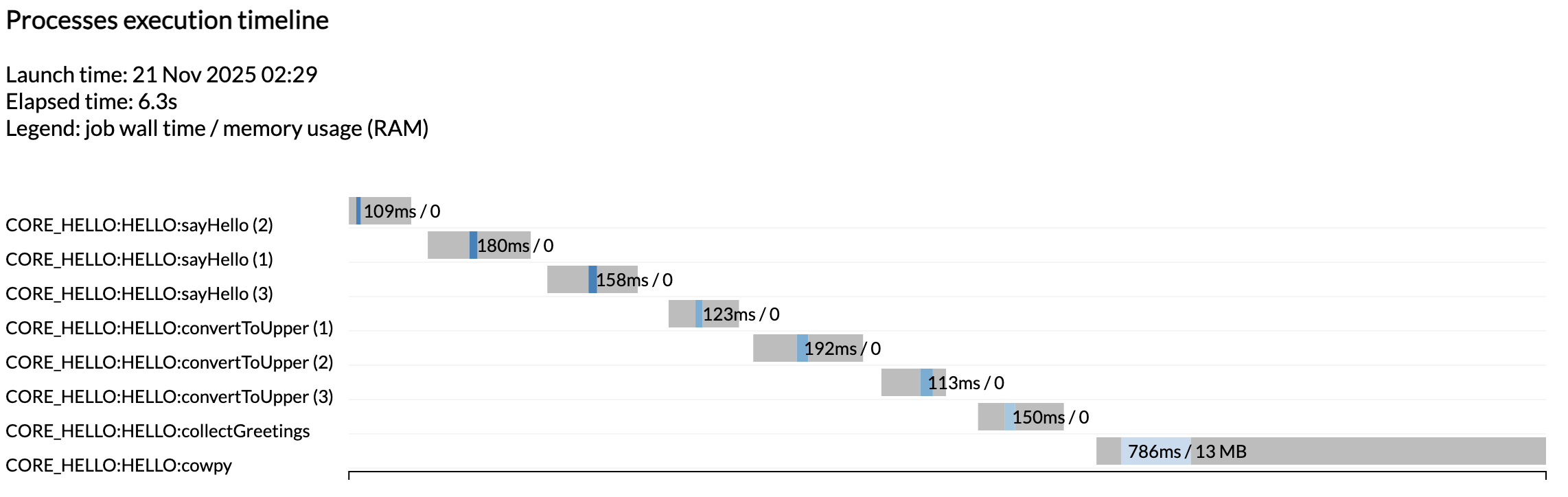
Uwaga
Ponownie zadania nie były uruchamiane równolegle, ponieważ działamy na minimalistycznej maszynie w Github Codespaces. Aby zobaczyć, jak te uruchamiają się równolegle, spróbuj zwiększyć alokację CPU Swojego codespace oraz limity zasobów w konfiguracji testowej.
To świetnie, ale nasze rzeczywiste wyniki pipeline'u tam nie są!
Oto co się stało: nie zmieniliśmy niczego w samych modułach, więc wyniki obsługiwane przez dyrektywy publishDir na poziomie modułów nadal trafiają do katalogu results, jak określono w oryginalnym pipeline'ie.
Zawartość katalogu
results
├── Bonjour-output.txt
├── COLLECTED-test-batch-output.txt
├── COLLECTED-test-output.txt
├── cowpy-COLLECTED-test-batch-output.txt
├── cowpy-COLLECTED-test-output.txt
├── Hello-output.txt
├── Hola-output.txt
├── UPPER-Bonjour-output.txt
├── UPPER-Hello-output.txt
└── UPPER-Hola-output.txt
0 directories, 10 files
Aha, są tutaj, pomieszane z wynikami wcześniejszych uruchomień oryginalnego pipeline'u Hello.
Jeśli chcemy, aby były starannie zorganizowane jak wyniki pipeline'u demo, będziemy musieli zmienić sposób konfiguracji publikowania wyników. Pokażemy Ci, jak to zrobić później w tym kursie szkoleniowym.
I to tyle! Może się wydawać, że to dużo pracy, aby osiągnąć ten sam rezultat co oryginalny pipeline, ale otrzymujesz wszystkie te ładne raporty generowane automatycznie i masz teraz solidny fundament do wykorzystania dodatkowych funkcji nf-core, w tym walidacji wejść oraz niektórych fajnych możliwości obsługi metadanych, które omówimy w późniejszej sekcji.
Podsumowanie¶
Wiesz, jak przekonwertować zwykły pipeline Nextflow na pipeline w stylu nf-core używając szablonu nf-core. W ramach tego nauczyłeś się, jak uczynić workflow kompozycyjnym oraz jak zidentyfikować elementy szablonu nf-core, które najczęściej wymagają dostosowania podczas tworzenia niestandardowego pipeline'u w stylu nf-core.
Co dalej?¶
Zrób sobie przerwę, to była ciężka praca! Kiedy będziesz gotowy, przejdź do Części 3: Użycie modułu nf-core, aby nauczyć się, jak wykorzystać moduły utrzymywane przez społeczność z repozytorium nf-core/modules.